Distributed System (8) More efficient B-multicasts B-multicast in physical network view: Redundant packets Tree-based multicast construct a minimum spanning tree and unicast along that. then, construct a tree that inclu 2024-02-22 Course Notes > Distributed Systems
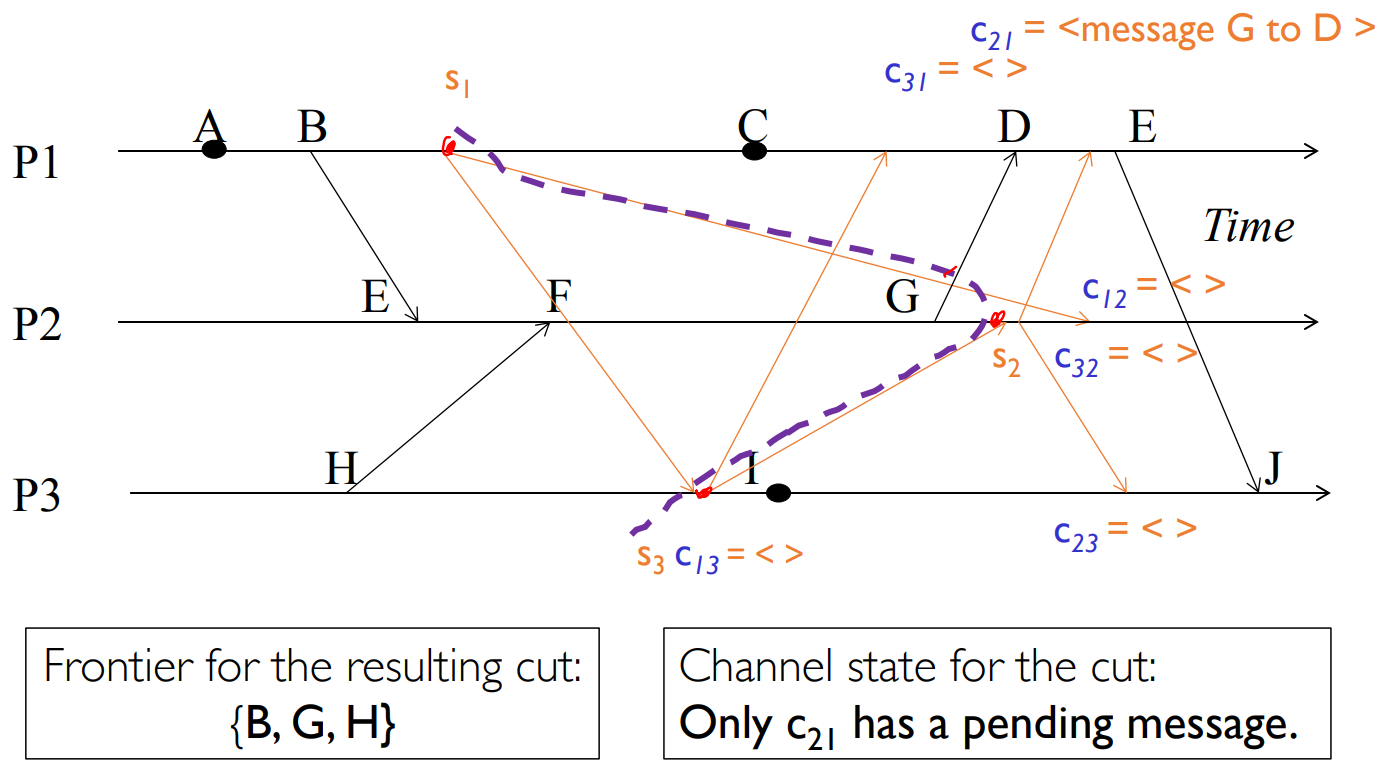
Distributed System (5) Chandy-Lamport Algorithm (Snapshot should not interfere with normal application actions, and it should not require application to stop sending messages.) First, initiator PiP_iPi : records its own s 2024-02-21 Course Notes > Distributed Systems
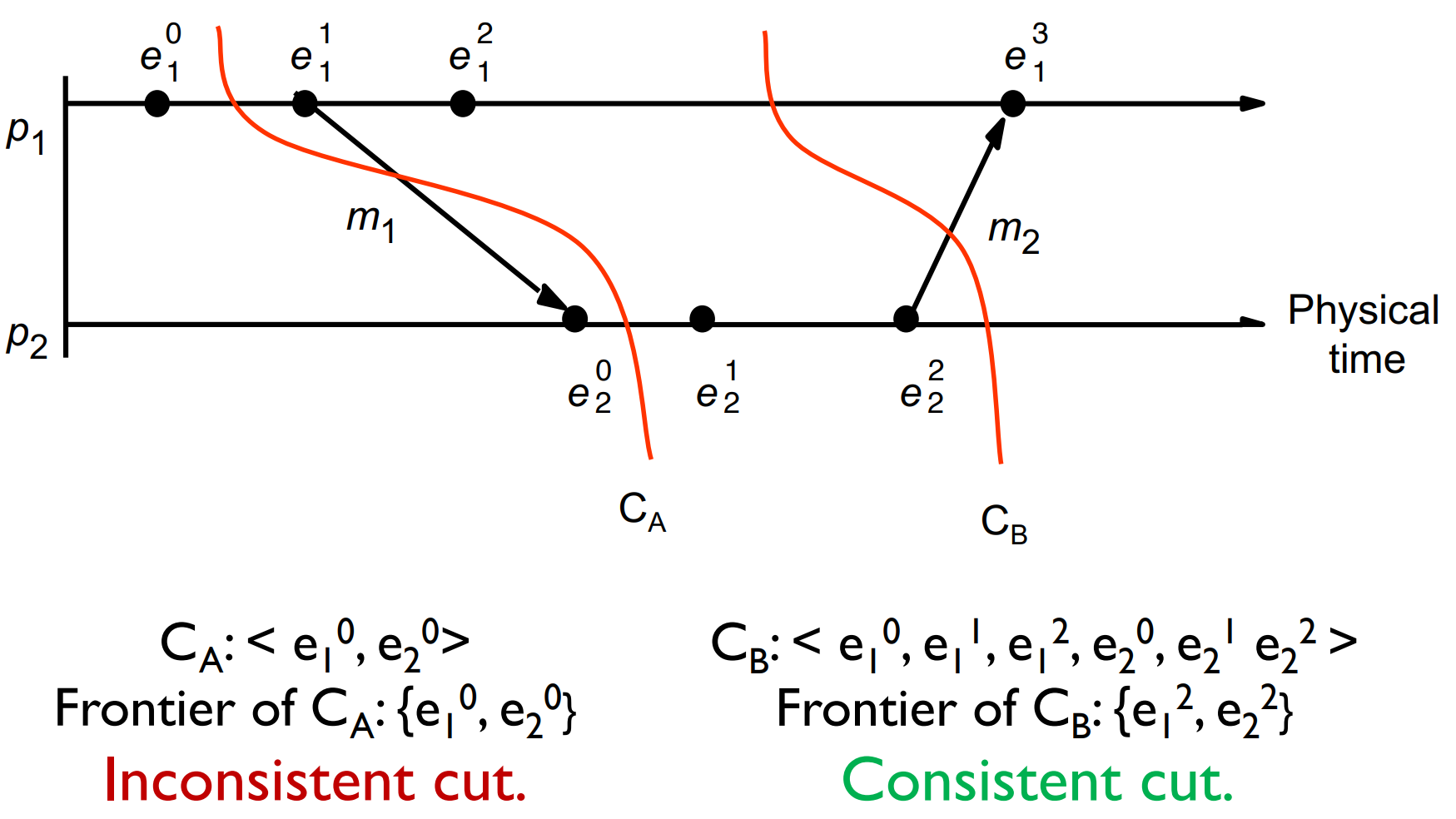
Distributed System (4) Event Ordering Three types of events: Local computation Sending a message Receiving a message Happened-Before Relationship e →\rightarrow→ e’ means e happened before e’. e →ie′\rightarrow_i e' 2024-02-20 Course Notes > Distributed Systems
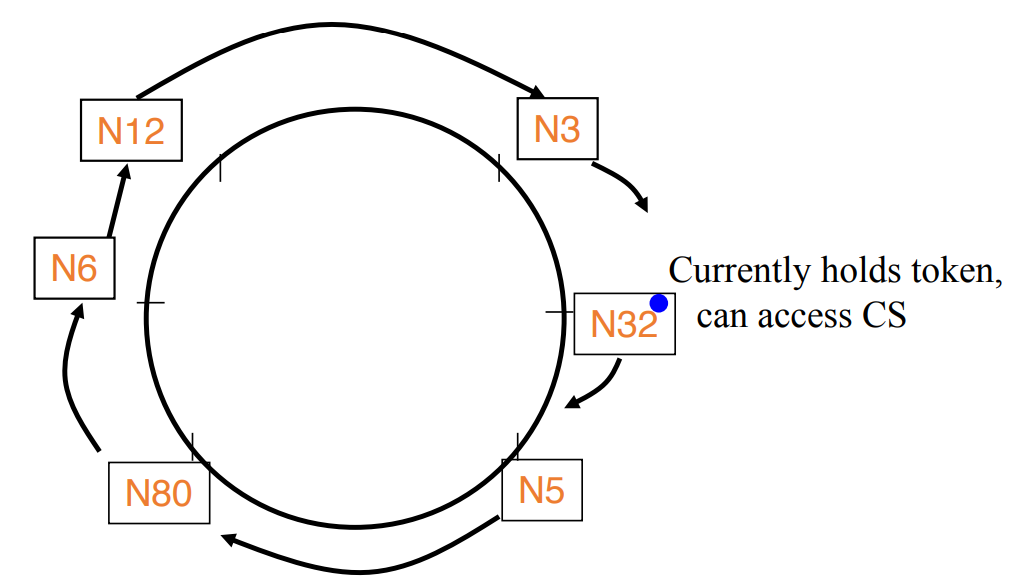
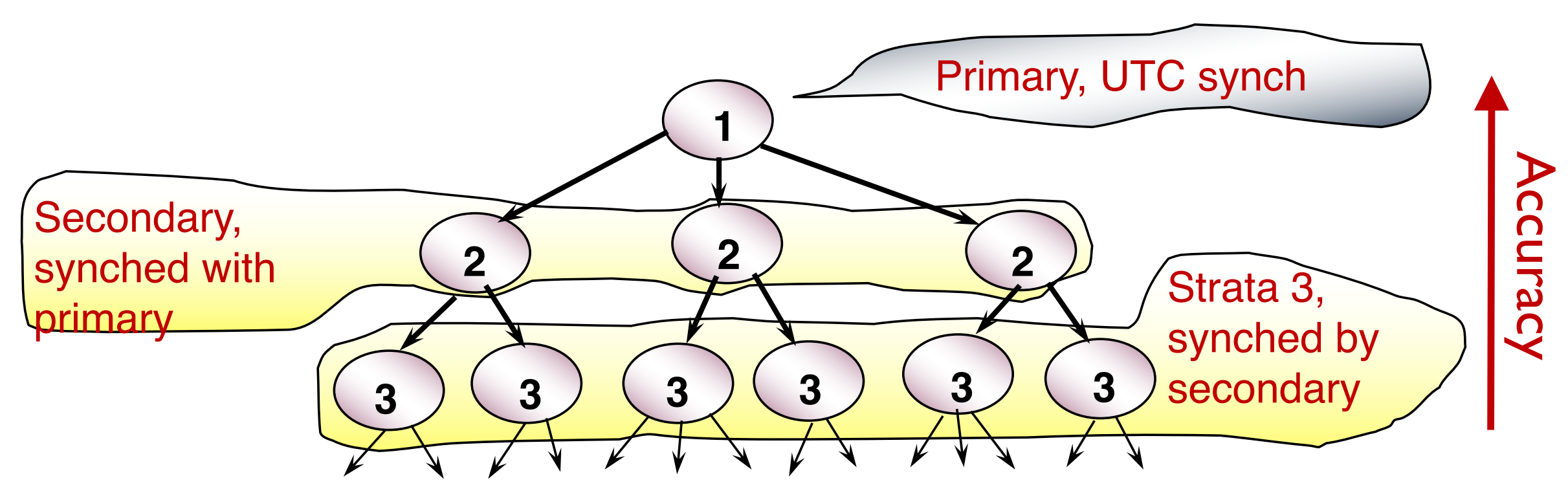
Distributed System (3) Omission Omission: when a process or a channel fails to perform actions that it is supposed to do. ping-ack or heartbeat Communication omission: mitigated by network protocols. Extending heart 2024-02-19 Course Notes > Distributed Systems
Communication Networks (8) Chapter 3: Transport Layer Transport services and protocols transport protocols run in end systems send side: breaks app messages into segments, passes to network layer rcv side: reassembles segment 2024-02-18 Course Notes > Communication Networks
Communication Networks (7) Pure P2P architecture no always-on server arbitrary end systems directly communicate peers are intermittently connected and change IP addresses File distribution: client-server vs P2P client-server 2024-02-18 Course Notes > Communication Networks
Communication Networks (6) Web caches (proxy server) browser sends all HTTP requests to cache object in cache: cache returns object else cache requests object from origin server, then returns object to client Conditional GE 2024-02-18 Course Notes > Communication Networks
Deep Learning for Computer Vision (3) Perceptron Recall the sigmiod loss. Define the perceptron hinge loss: l(w,xi,yi)=max(0,−yiwTxi)l\left(w, x_i, y_i\right)=\max \left(0,-y_i w^T x_i\right) l(w,xi,yi)=max(0,−yiwTxi) Training proce 2024-02-14 Course Notes > Deep Learning for CV
Reinforcemant Learning (9) recap in policy iteration, appply greedy algo very time. #steps are finite. another proof performance-difference lemma (P-D lemma) this is a fundamental tool in RL. many deep RL models relies on this 2024-02-13 Course Notes > Reinforcement Learning
Reinforcement Learning (8) Policy Iteration π0:S→A\pi_0: S \to A π0:S→A steps: policy evaluation: Compute Qπk−1∈RSAQ^{\pi_{k-1}}\in \mathbb{R}^{SA}Qπk−1∈RSA policy improvement: πk←πQπk−1\pi_k \leftarrow \pi_{Q^{\pi_{k-1}}}πk 2024-02-11 Course Notes > Reinforcement Learning