Distributed System (5)
Chandy-Lamport Algorithm
(Snapshot should not interfere with normal application actions, and it should not require application to stop sending messages.)
First, initiator :
- records its own state
- creates a special marker message.
- for
- sends a marker message on outgoing channel
- start recording
For other process receiving a marked message from channel ,
- if it is the first time see marked message
- records its own state
- marks the state of as “empty”
- for
- sends a marked message over
- if
- start recording
- else
- stop recording (the state of channel contains all messages during recording)
<video controls src…/img/post/distributed-system-5-output.mp4" title=“Chandy-Lamport Algorithm” width=“60%”>
Any run of the Chandy-Lamport Global Snapshot algorithm creates a consistent cut.
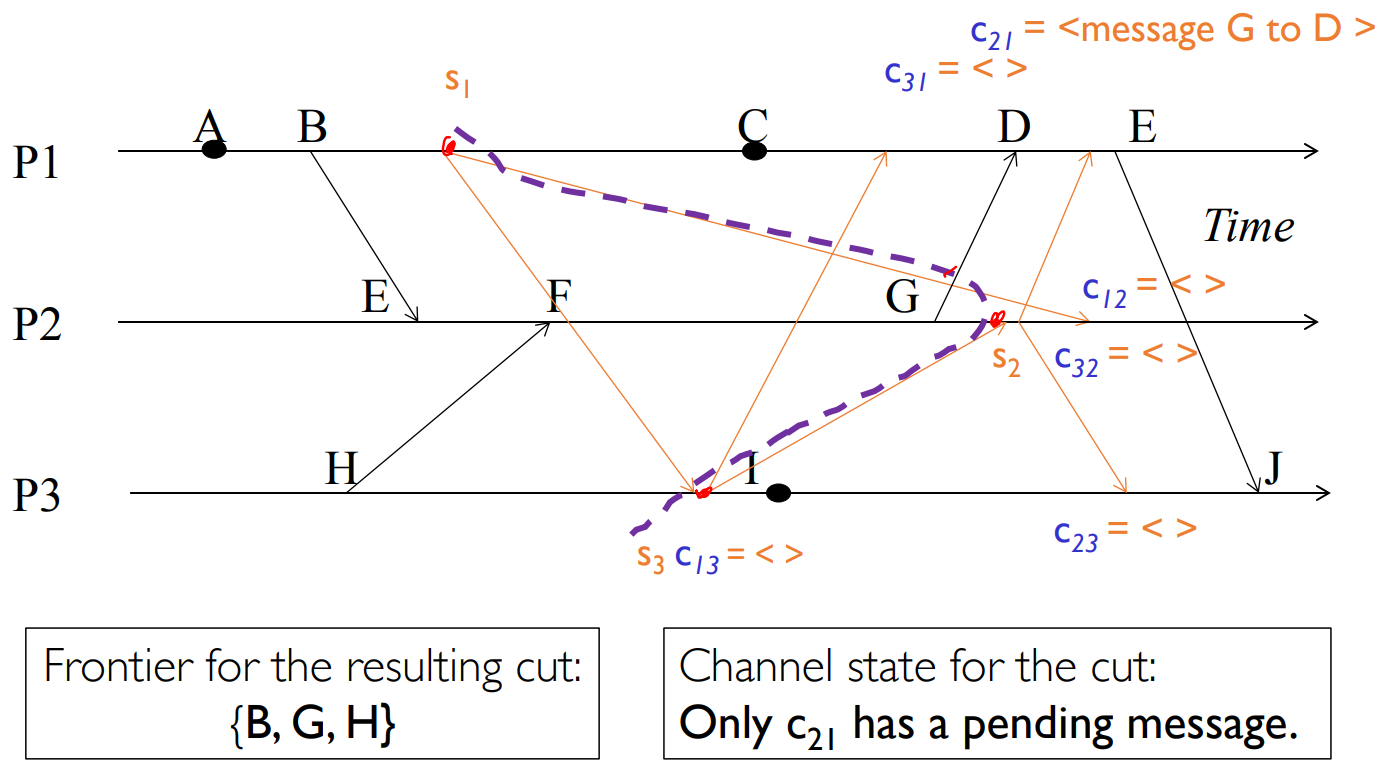
Proof.
- for every pair of causal messages corresponding to process , if is in the cut, then is also in the cut.
- prove by contracdition: if not, was sent before sending the marked message but arrive before it, then the cannel is not FIFO.
linearization
- A run is a total ordering of events in the global history that is consistent with each ’s ordering.
• A linearization is a run consistent with happens-before
( ) relation in .

- Run: (keeping the order within each process suffies)
- Linearization:
Execution Lattice
Each path represents a linearization.


An lattice of


Distributed System (5)
https://yzzzf.xyz/2024/02/21/distributed-system-5/