Recall the Bellman Equation:
(Tπf)(s,a)=R(s,a)+γEs′∼P(k,a)[f(s′,π)]=E[r+γ⋅f(s′,π)∣s,a].
with empirically equals to:
n1i=1∑n(ri+γθk1(si′,π)).
with tuples (st,at,rt,st+1) in the long trajectory, applying the running average:
Qk(st,at)←Qk(st,at)+α(rt+γQk−1(st+1,π)−Qk(st,at))
SARSA
Q(st,at)←Q(st,at)+α(rt+γQ(st+1,at+1)−Q(st,at))
Notice that SARSA is not applicable for deterministic policy, because it requires a non-zero probability distribution over all st0ate-action pairs ( ∀(s,a)∈S×A ), but the only possible action for a certain state is determined by the policy.
SARSA with ϵ -greedy policy
How are the s,a data pairs picked in SARSA?
At each time step t, with probability ϵ , choose a from the action space uniformly at random. otherwise, at=argmaxaQ(st,a)
When sampling s-a-r-s-a tuple along the trajectory, the first action in the tuple is actually generated with last version of Q , so we can say SARSA is not 100% “on policy”.
{: .prompt-info }
Does SARSA converge to optimal policy?
The cliff example (pg 132 of Sutton & Barto)
- Deterministic navigation, high penalty when falling off the clif
- Optimal policy: walk near the cliff
- Unless epsilon is super small, SARSA will avoid the cliff
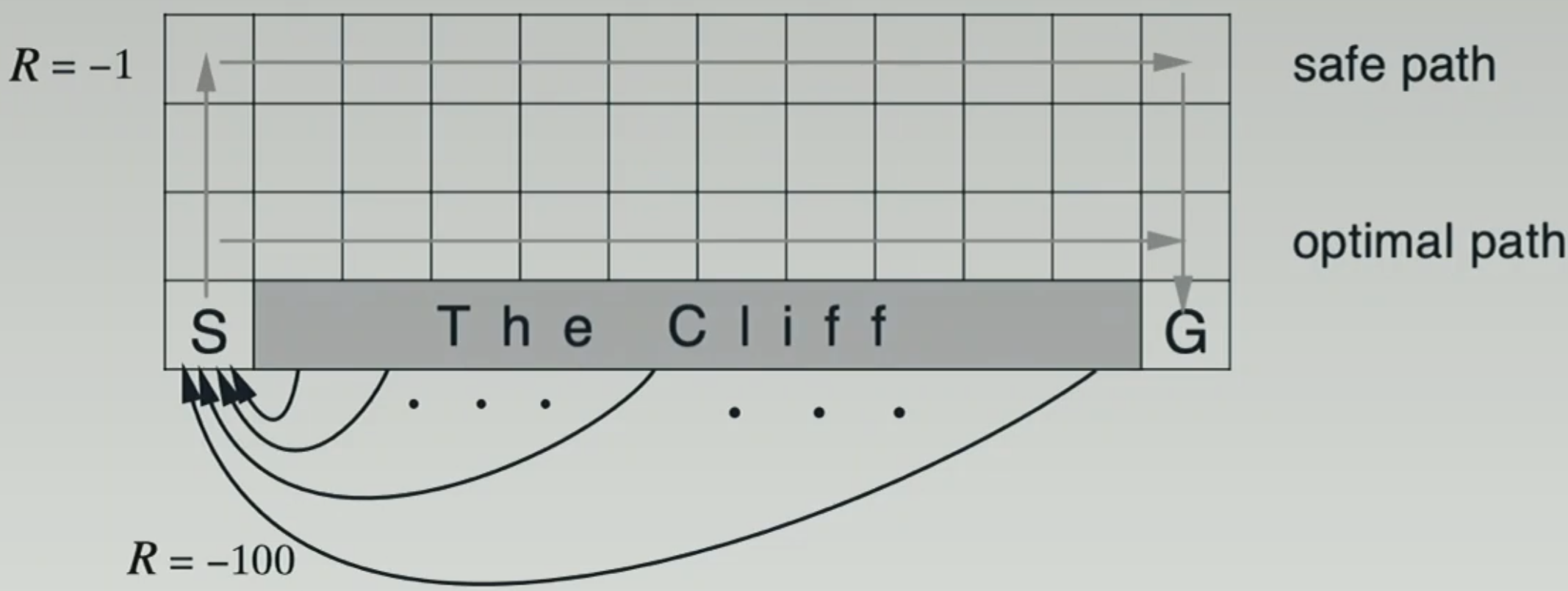
cliff example
The optimal path is along the side of the cliff, but on this path, the ϵ -greedy SARSA will often see large penalty (falling off the cliff) and therefore, choose the safe path instead.
softmax
ϵ-greedy can be replaged by softmax: chooses action a with probability
∑a′exp(Q(s,a′)/T)exp(Q(s,a)/T)
where T is temperature.