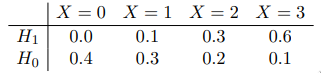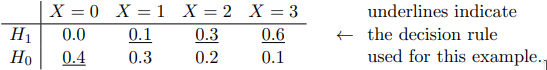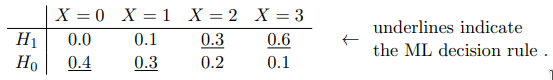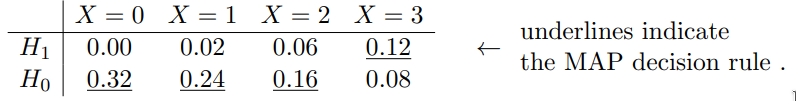De morgan
A c ∩ B c = ( A ∪ B ) c A^c\cap B^c = (A\cup B)^c
A c ∩ B c = ( A ∪ B ) c
probability space ( Ω , F , P ) (\Omega, \mathcal{F}, P) ( Ω , F , P )
Ω \Omega Ω
F \mathcal{F} F
$P − p r o b a b i l i t y m e a s u r e o n - probability measure on − p ro babi l i t y m e a s u reo n
power set denoted as 2 Ω 2^\Omega 2 Ω
∣ 2 Ω ∣ = 2 ∣ Ω ∣ |2^\Omega| = 2^{|\Omega|}
∣ 2 Ω ∣ = 2 ∣Ω∣
$A, B a r e m u t u a l l y e x c l u s i v e : are mutually exclusive: a re m u t u a ll ye x c l u s i v e : ( n o t (not ( n o t
Axioms
event axioms
Ω ∈ F \Omega \in \mathcal{F} Ω ∈ F A ∈ F ⇒ A c ∈ F A\in \mathcal{F} \Rightarrow A^c \in \mathcal{F} A ∈ F ⇒ A c ∈ F A , B ∈ F ⇒ A ∪ B ∈ F A, B \in \mathcal{F} \Rightarrow A \cup B \in \mathcal{F} A , B ∈ F ⇒ A ∪ B ∈ F can prove:
∅ ∈ F \emptyset \in \mathcal{F} ∅ ∈ F A , B ∈ F ⇒ A B ∈ F A,B \in \mathcal{F} \Rightarrow AB \in \mathcal{F} A , B ∈ F ⇒ A B ∈ F
probability axioms
P ( A ) ≥ 0 ∀ A ∈ F P(A) \ge 0\quad \forall A \in \mathcal{F} P ( A ) ≥ 0 ∀ A ∈ F A B = ∅ ⇒ P ( A ∪ B ) = P ( A ) + P ( B ) AB = \emptyset \Rightarrow P(A\cup B) = P(A) + P(B) A B = ∅ ⇒ P ( A ∪ B ) = P ( A ) + P ( B ) P ( Ω ) = 1 P(\Omega)=1 P ( Ω ) = 1 can prove:
P ( A c ) = 1 − P ( A ) P(A^c) = 1 - P(A) P ( A c ) = 1 − P ( A ) P ( A ) = P ( A B ) + P ( A B c ) P(A) = P(AB) + P(AB^c) P ( A ) = P ( A B ) + P ( A B c ) P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A B ) P(A\cup B) = P(A) + P(B) - P(AB) P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A B )
Principle of counting: multiply
Counting
permutation - factorials
binomial coefficient
K map
Random Variables
for a probability space ( Ω , F , P ) (\Omega, \mathcal{F}, P) ( Ω , F , P )
$r.v i s a r e a l − v a l u e d f u n c t i o n o n is a real-valued function on i s a re a l − v a l u e df u n c t i o n o n
X : Ω → R X: \Omega \to \mathbb{R}
X : Ω → R
Variance and Standard Deviation
V a r ( X ) : = E [ ( X − E [ X ] ) 2 ] σ X = V a r ( X ) Var(X) := E[(X-E[X])^2] \\ \sigma_X = \sqrt{Var(X)}
Va r ( X ) := E [( X − E [ X ] ) 2 ] σ X = Va r ( X )
Properties of Variance
V a r ( a X + b ) = a 2 V a r ( X ) Var(aX+b) = a^2Var(X)
Va r ( a X + b ) = a 2 Va r ( X )
V a r ( X ) = E [ ( X − E [ X ] ) 2 ] = E [ X 2 − 2 X E [ X ] + E [ X ] 2 ] = E [ X 2 ] − 2 E [ X ] E [ X ] + E [ X ] 2 = E [ X 2 ] − E [ X ] 2 \begin{aligned} Var(X) &= E[(X-E[X])^2] \\&=E[X^2-2XE[X]+E[X]^2] \\&=E[X^2] - 2E[X]E[X] + E[X]^2 \\&= E[X^2] - E[X]^2 \end{aligned}
Va r ( X ) = E [( X − E [ X ] ) 2 ] = E [ X 2 − 2 XE [ X ] + E [ X ] 2 ] = E [ X 2 ] − 2 E [ X ] E [ X ] + E [ X ] 2 = E [ X 2 ] − E [ X ] 2
e.g. 4 people poicking 4 card with name, expectation of # of people picking a card with their name.
X i = { 1 c h o o s e n a m e 0 o t h e r w i s e X_i = \begin{cases}1 & choosename \\0&otherwise\end{cases}
X i = { 1 0 c h oose nam e o t h er w i se
then
X = ∑ i = 1 4 X i X = \sum_{i=1}^4X_i
X = i = 1 ∑ 4 X i
E [ X ] = ∑ i = 1 4 E [ X i ] = ∑ i = 1 4 1 4 = 1 E[X] = \sum_{i=1}^4E[X_i] = \sum_{i=1}^4 \frac{1}{4}= 1
E [ X ] = i = 1 ∑ 4 E [ X i ] = i = 1 ∑ 4 4 1 = 1
Variance:
because
X i 2 = X i X_i^2 = X_i
X i 2 = X i
therefore
E [ X i 2 ] = 1 4 E[X_i^2] = \frac{1}{4}
E [ X i 2 ] = 4 1
X i X j = { 1 both i,j choose their name 0 o t h e r w i s e X_iX_j = \begin{cases}1 & \text{both i,j choose their name} \\0&otherwise\end{cases}
X i X j = { 1 0 both i,j choose their name o t h er w i se
and
E [ X i X j ] = 1 4 1 3 = 1 12 E[X_iX_j] = \frac{1}{4} \frac{1}{3} = \frac{1}{12}
E [ X i X j ] = 4 1 3 1 = 12 1
E [ X 2 ] = ∑ i = 1 4 E [ X i 2 ] + ∑ i ≠ j E [ X i X j ] = 4 ⋅ 1 4 + 12 ⋅ 1 12 = 2 \begin{aligned}
E[X^2] = \sum_{i=1}^4E[X_i^2]+\sum _{i\ne j}E[X_iX_j] \\
= 4 \cdot \frac{1}{4} + 12 \cdot \frac{1}{12} = 2
\end{aligned}
E [ X 2 ] = i = 1 ∑ 4 E [ X i 2 ] + i = j ∑ E [ X i X j ] = 4 ⋅ 4 1 + 12 ⋅ 12 1 = 2
V a r ( X ) = 2 − 1 2 = 1 Var(X) = 2 - 1^2 = 1
Va r ( X ) = 2 − 1 2 = 1
Conditional Probability
Conditional Probability of B given A is defined as
P ( B ∣ A ) = { P ( A B ) P ( A ) if P ( A ) > 0 undefined P(B|A) = \begin{cases} \frac{P(AB)}{P(A)} &\text{if} P(A) > 0 \\ \text{undefined}\end{cases}
P ( B ∣ A ) = { P ( A ) P ( A B ) undefined if P ( A ) > 0
Independent event
P ( B ∣ A ) = P ( B ) P(B|A) = P(B)
P ( B ∣ A ) = P ( B )
Independent variable
for any A , B ⊂ R A,B \subset \mathbb{R} A , B ⊂ R X ∈ A X \in A X ∈ A Y ∈ B Y \in B Y ∈ B
this implies P X Y ( x , y ) = P X ( x ) P Y ( y ) P_{XY}(x,y) = P_X(x)P_Y(y) P X Y ( x , y ) = P X ( x ) P Y ( y )
Properties of r.v
independent: E [ X Y ] = E [ X ] E [ Y ] E[XY]=E[X]E[Y] E [ X Y ] = E [ X ] E [ Y ]
not necessarily independent: E [ X + Y ] = E [ X ] + E [ Y ] E[X+Y]=E[X]+E[Y] E [ X + Y ] = E [ X ] + E [ Y ]
independent: V a r [ X + Y ] = V a r [ X ] + V a r [ Y ] Var[X+Y]=Var[X]+Var[Y] Va r [ X + Y ] = Va r [ X ] + Va r [ Y ]
Bernoulli Distribution A r.v. X X X X = { 0 , 1 } \mathcal{X}= \{0,1\} X = { 0 , 1 }
p X ( 1 ) = p , p X ( 0 ) = 1 − p p_X(1) = p, \quad p_X(0) = 1-p
p X ( 1 ) = p , p X ( 0 ) = 1 − p
E [ X ] = p , V a r ( X ) = p ( 1 − p ) E[X] = p ,\quad Var(X) = p(1-p)
E [ X ] = p , Va r ( X ) = p ( 1 − p )
The Binomial Distribution
r.v. Y Y Y
$n i n d e p e n d e n t e x p e r i m e n t s , e a c h i s independent experiments, each is in d e p e n d e n t e x p er im e n t s , e a c hi s
X X X
pmf of X X X
p X ( k ) = ( n k ) p k ( 1 − p ) n − k p_X(k) = \binom{n}{k} p^k(1-p)^{n-k}
p X ( k ) = ( k n ) p k ( 1 − p ) n − k
E [ X ] = n p , V a r ( X ) = n p ( 1 − p ) E[X] = np, \quad Var(X) = np(1-p)
E [ X ] = n p , Va r ( X ) = n p ( 1 − p )
Geometric Distribution
Sequence of independent experiments each having a Bernoulli distribution with p p p L L L
p L ( k ) = ( 1 − p ) k − 1 p for k ≥ 1. P { L > k } = ( 1 − p ) k for k ≥ 0. \begin{aligned}
p_L(k) & =(1-p)^{k-1} p \quad \text { for } \quad k \geq 1 . \\
P\{L>k\} & =(1-p)^k \quad \text { for } \quad k \geq 0 .
\end{aligned}
p L ( k ) P { L > k } = ( 1 − p ) k − 1 p for k ≥ 1. = ( 1 − p ) k for k ≥ 0.
E [ L ] = 1 p , V a r ( L ) = 1 − p p 2 E[L] = \frac{1}{p}, \quad Var(L) = \frac{1-p}{p^2}
E [ L ] = p 1 , Va r ( L ) = p 2 1 − p
Poisson Distribution
For each r.v. X 1 , X 2 , ⋯ X_1, X_2, \cdots X 1 , X 2 , ⋯
C j : = ∑ k = 1 j X k C_j := \sum_{k=1}^j X_k
C j := k = 1 ∑ j X k
p ( k ) = λ k e − λ k ! , λ = n p p(k) = \frac{\lambda ^ke^{-\lambda}}{k!}, \; \lambda = np
p ( k ) = k ! λ k e − λ , λ = n p
E [ Y ] = λ , V a r ( Y ) = λ E[Y]=\lambda,\;Var(Y)=\lambda
E [ Y ] = λ , Va r ( Y ) = λ
is λ \lambda λ p p p λ \lambda λ p p p
Negative Binomial Distribution
number of failures in a sequence of independent and identically distributed Bernoulli trials before a specified (non-random) number of successes (denoted r ) occurs.
f ( k ; r , p ) ≡ Pr ( X = k ) = ( k + r − 1 r − 1 ) p r ( 1 − p ) k f(k; r, p) \equiv \Pr(X = k) = \binom{k+r-1}{r-1} p^r(1-p)^k
f ( k ; r , p ) ≡ Pr ( X = k ) = ( r − 1 k + r − 1 ) p r ( 1 − p ) k
E [ k ] = r 1 − p p E[k] = r \frac{1-p}{p}
E [ k ] = r p 1 − p
V a r ( k ) = r 1 − p p 2 Var(k) = r \frac{1-p}{p^2}
Va r ( k ) = r p 2 1 − p
Maximum Likelihood Parameter Estimation
$f i s t h e d i s t r i b u t i o n o f is the distribution of i s t h e d i s t r ib u t i o n o f
L : θ ↦ f ( x ∣ θ ) θ ^ M L ( x ) = arg max θ f ( x ∣ θ ) L: \theta \mapsto f(x | \theta) \\
\hat{\theta}_{\mathrm{ML}}(x) = \argmax_{\theta} f(x | \theta)
L : θ ↦ f ( x ∣ θ ) θ ^ ML ( x ) = θ arg max f ( x ∣ θ )
Markov inequality
if Y Y Y c > 0 c>0 c > 0
P r { Y ≥ c } ≤ E [ Y ] c Pr\{Y\ge c\} \le \frac{E[Y]}{c}
P r { Y ≥ c } ≤ c E [ Y ]
Proof.
E ( X ) = ∫ − ∞ ∞ x f ( x ) d x = ∫ 0 ∞ x f ( x ) d x ⩾ ∫ a ∞ x f ( x ) d x ⩾ ∫ a ∞ a f ( x ) d x = a ∫ a ∞ f ( x ) d x = a P ( X ⩾ a ) . \begin{aligned}\textrm{E}(X) &= \int_{-\infty}^{\infty}x f(x) dx \\&= \int_{0}^{\infty}x f(x) dx \\[6pt]&\geqslant \int_{a}^{\infty}x f(x) dx \\[6pt]&\geqslant \int_{a}^{\infty}a f(x) dx \\[6pt]&= a\int_{a}^{\infty} f(x) dx \\[6pt]&=a\textrm{P}(X\geqslant a).\end{aligned}
E ( X ) = ∫ − ∞ ∞ x f ( x ) d x = ∫ 0 ∞ x f ( x ) d x ⩾ ∫ a ∞ x f ( x ) d x ⩾ ∫ a ∞ a f ( x ) d x = a ∫ a ∞ f ( x ) d x = a P ( X ⩾ a ) .
Chebyshev’s Inequality
Pr ( ∣ X − E ( X ) ∣ ≥ a ) ≤ Var ( X ) a 2 \Pr(|X-\textrm{E}(X)| \geq a) \leq \frac{\textrm{Var}(X)}{a^2}
Pr ( ∣ X − E ( X ) ∣ ≥ a ) ≤ a 2 Var ( X )
Proof.
Var ( X ) = E [ ( X − E ( X ) ) 2 ] . \operatorname{Var}(X) = \operatorname{E}[(X - \operatorname{E}(X) )^2].
Var ( X ) = E [( X − E ( X ) ) 2 ] .
use Markov inequality,
Pr ( ( X − E ( X ) ) 2 ≥ a 2 ) ≤ Var ( X ) a 2 , \Pr( (X - \operatorname{E}(X))^2 \ge a^2) \le \frac{\operatorname{Var}(X)}{a^2},
Pr (( X − E ( X ) ) 2 ≥ a 2 ) ≤ a 2 Var ( X ) ,
Confidence Interval
With r.v. p ^ = X n \hat p = \frac{X}{n} p ^ = n X μ = E [ p ^ ] = p \mu = E[\hat p] = p μ = E [ p ^ ] = p
then
V a r ( p ^ ) = V a r ( X ) n = p ( 1 − p ) n Var(\hat p) = \frac{Var(X)}{n} = \frac{p(1-p)}{n}
Va r ( p ^ ) = n Va r ( X ) = n p ( 1 − p )
and`
Pr { ∣ p ^ − μ ∣ < σ b } > 1 − 1 b 2 ⇒ Pr { μ ∈ ( p ^ − σ b , p ^ + σ b ) } > 1 − 1 b 2 ⇒ Pr { p ∈ ( p ^ − b p ( 1 − p ) n , p ^ + b p ( 1 − p ) n ) } > 1 − 1 b 2 \begin{array}{c}\operatorname{Pr}\left\{\left|\hat{p}^{}-\mu\right|<\sigma b\right\}>1-\frac{1}{b^{2}} \\\Rightarrow \operatorname{Pr}\{\mu \in(\hat{p}-\sigma b, \hat{p}+\sigma b)\}>1-\frac{1}{b^{2}} \\\Rightarrow \operatorname{Pr}\left\{p \in\left(\hat{p}-b \sqrt{\frac{p(1-p)}{n}}, \hat{p}+b \sqrt{\frac{p(1-p)}{n}}\right)\right\}>1-\frac{1}{b^{2}}\end{array}
Pr { ∣ p ^ − μ ∣ < σb } > 1 − b 2 1 ⇒ Pr { μ ∈ ( p ^ − σb , p ^ + σb )} > 1 − b 2 1 ⇒ Pr { p ∈ ( p ^ − b n p ( 1 − p ) , p ^ + b n p ( 1 − p ) ) } > 1 − b 2 1
Use bound p ( 1 − p ) ≤ 1 2 \sqrt{p(1-p)} \le \frac{1}{2} p ( 1 − p ) ≤ 2 1
Pr { p ∈ ( p ^ − b 2 n , p ^ + b 2 n ) } > 1 − 1 b 2 \operatorname{Pr}\left\{p \in\left(\hat{p}-\frac{b}{2 \sqrt{n}}, \hat{p}+\frac{b}{2 \sqrt{n}}\right)\right\}>1-\frac{1}{b^{2}}
Pr { p ∈ ( p ^ − 2 n b , p ^ + 2 n b ) } > 1 − b 2 1
$1-\frac{1}{b^2} i s c o n f i d e n c e l e v e l , is confidence level, i sco n f i d e n ce l e v e l ,
Conditional mean
E [ X ∣ A ] = ∑ i u i P ( X = u i ∣ A ) E[X|A] = \sum_i u_iP(X=u_i|A)
E [ X ∣ A ] = i ∑ u i P ( X = u i ∣ A )
LOTUS (Law of the unconscious statistician)
E [ g ( X ) ∣ A ] = ∑ i g ( u i ) P ( X = u i ∣ A ) E[g(X)|A] = \sum_i g(u_i)P(X=u_i|A)
E [ g ( X ) ∣ A ] = i ∑ g ( u i ) P ( X = u i ∣ A )
Total Probability Theroem
P ( B ) = ∑ i P ( A i B ) P ( B ) = ∑ i P ( B ∣ A i ) P ( A i ) P(B) = \sum_i{P(A_iB)} \\P(B) = \sum_i{P(B|A_i)P(A_i)}
P ( B ) = i ∑ P ( A i B ) P ( B ) = i ∑ P ( B ∣ A i ) P ( A i )
Response of Stochastic System
Bayes’ theorem
P ( A ∣ B ) = P ( B ∣ A ) P ( A ) P ( B ) = P ( A i ) P ( B ∣ A i ) ∑ i P ( B ∣ A i ) P ( A i ) P(A|B) = \frac{P(B|A)P(A)}{P(B)} =\frac{P(A_i)P(B|A_i)}{\sum_iP(B|A_i)P(A_i)}
P ( A ∣ B ) = P ( B ) P ( B ∣ A ) P ( A ) = ∑ i P ( B ∣ A i ) P ( A i ) P ( A i ) P ( B ∣ A i )
MAP v.s ML
ML
L : θ ↦ P ( x ∣ θ ) θ ^ = arg max θ P ( x ∣ θ ) L:\theta \mapsto P(x|\theta) \\ \hat \theta =\argmax_\theta P(x|\theta)
L : θ ↦ P ( x ∣ θ ) θ ^ = θ arg max P ( x ∣ θ )
MAP
L : θ ↦ P ( θ ∣ x ) θ ^ = arg max θ P ( θ ∣ x ) = arg max θ P ( x ∣ θ ) P ( θ ) ∑ θ ′ P ( x ∣ θ ′ ) g ( θ ′ ) L:\theta \mapsto P(\theta|x) \\ \hat \theta =\argmax_\theta P(\theta|x) = \argmax_\theta \frac{P(x|\theta)P(\theta)}{\sum_{\theta'}P(x|\theta')g(\theta ')}
L : θ ↦ P ( θ ∣ x ) θ ^ = θ arg max P ( θ ∣ x ) = θ arg max ∑ θ ′ P ( x ∣ θ ′ ) g ( θ ′ ) P ( x ∣ θ ) P ( θ )
Network Probability
edge i has a probability p i p_i p i
Boole’s Inequality (Union Bound)
P ( ⋃ i A i ) ≤ ∑ i P ( A i ) P\left(\bigcup_{i} A_i\right) \le \sum_i P(A_i)
P ( i ⋃ A i ) ≤ i ∑ P ( A i )
Binary hypothesis testing with discrete-type observations
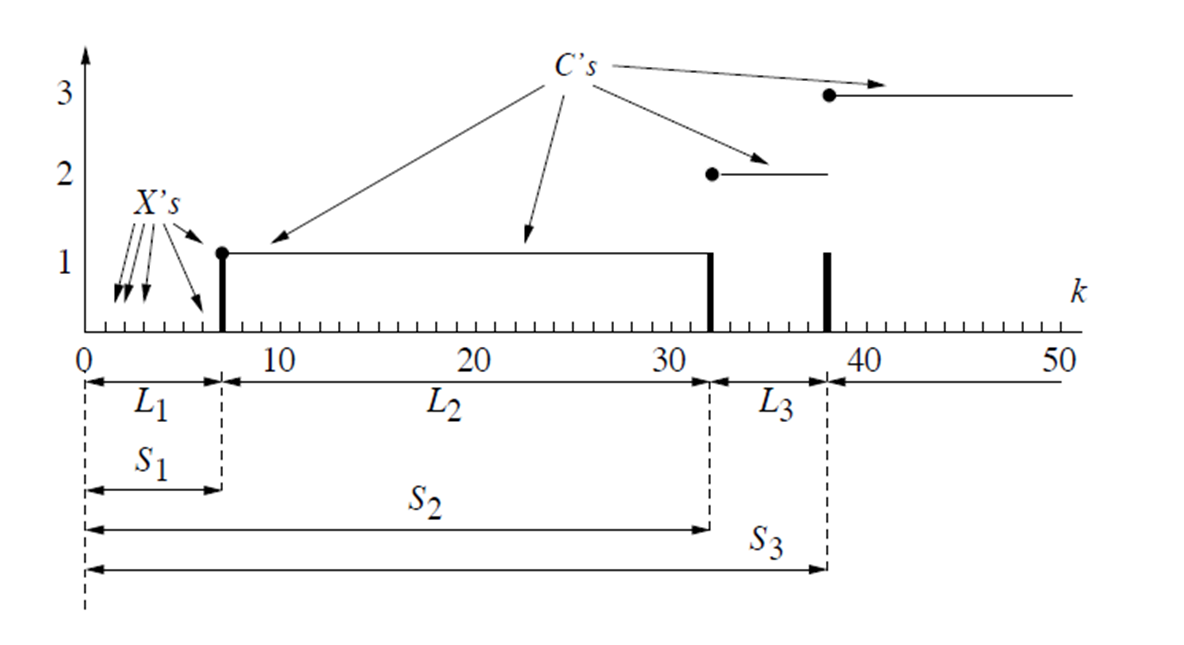
Likelihood matrix
Either hypothesis H 0 H_0 H 0 H 1 H_1 H 1 H 0 H_0 H 0 X X X p 0 p_0 p 0 H 0 H_0 H 0 X X X p 0 p_0 p 0
Decision rule
As mentioned above, a decision rule specifies, for each possible observation, which hypothesis is declared.
false alarm : H 0 H_0 H 0 H 1 H_1 H 1 miss : H 1 H_1 H 1 H 0 H_0 H 0
p false alarm = P ( declare H 1 true ∣ H 0 ) p miss = P ( declare H 0 true ∣ H 1 ) p_{\text{false alarm} } = P(\text{declare} H_1 \text{true} | H_0) \\ p_{\text{miss} } = P(\text{declare} H_0 \text{true} | H_1)
p false alarm = P ( declare H 1 true ∣ H 0 ) p miss = P ( declare H 0 true ∣ H 1 )
Maximum likelihood (ML) decision rule
ML decision rule
another way: likelihood ratio test (LRT)
Define the likelihood ratio
Λ ( k ) = p 1 ( k ) p 0 ( k ) \Lambda(k) = \frac{p_1(k)}{p_0(k)}
Λ ( k ) = p 0 ( k ) p 1 ( k )
Λ ( X ) { > 1 declare H 1 is true < 1 declare H 0 is true. \Lambda(X) \begin{cases}>1 & \text { declare } H_1 \text { is true } \\ <1 & \text { declare } H_0 \text { is true. }\end{cases}
Λ ( X ) { > 1 < 1 declare H 1 is true declare H 0 is true.
or
Λ ( X ) { > τ declare H 1 is true < τ declare H 0 is true \Lambda(X) \begin{cases}>\tau & \text { declare } H_1 \text { is true } \\ <\tau & \text { declare } H_0 \text { is true }\end{cases}
Λ ( X ) { > τ < τ declare H 1 is true declare H 0 is true
ML decision rule is τ = 1 \tau = 1 τ = 1
increase τ \tau τ miss
decrease τ \tau τ false alarm
Maximum a posteriori probability (MAP) decision rule
make use of P ( H 0 ) P(H_0) P ( H 0 ) P ( H 0 ) P(H_0) P ( H 0 ) prior knowledge and use joint probability such as P ( { X = 1 } ∩ H 1 ) P(\{X=1\}\cap H_1) P ({ X = 1 } ∩ H 1 )
denote
P ( H 0 ) = π i P(H_0) = \pi_i
P ( H 0 ) = π i
the joint probabilities are
P ( H i , X = k ) = π i p i ( k ) P(H_i, X=k) = \pi_ip_i(k)
P ( H i , X = k ) = π i p i ( k )
joint probability matrix π 0 = 0.8 , π 1 = 0.2 \pi_0 = 0.8, \pi_1 = 0.2 π 0 = 0.8 , π 1 = 0.2
equivalent to
τ = π 0 π 1 \tau = \frac{\pi_0}{\pi_1}
τ = π 1 π 0
‘uniform’ means π 0 = π 1 \pi_0 = \pi_1 π 0 = π 1
average error probability p e p_e p e
p e = π 0 p false alarm + π 1 p miss p_{e}=\pi_{0} p_{\text {false alarm }}+\pi_{1} p_{\text {miss }}
p e = π 0 p false alarm + π 1 p miss
minimize p e p_e p e ⟺ \iff ⟺
π 0 P ( declare H 0 ∣ H 0 ) + π 1 P ( declare H 1 ∣ H 1 ) = ∑ k π 0 P ( X = k ∣ H 0 ) P ( declare H 0 ∣ X = k ) + π 1 P ( X = k ∣ H 1 ) P ( declare H 1 ∣ X = k ) \begin{aligned}& \pi_0 P(\text{declare} H_0|H_0) + \pi_1 P(\text{declare} H_1|H_1) \\=&\sum_k \pi_0 P(X=k|H_0)P(\text{declare} H_0|X=k) + \\&\pi_1 P(X=k|H_1)P(\text{declare} H_1|X=k) \\\end{aligned}
= π 0 P ( declare H 0 ∣ H 0 ) + π 1 P ( declare H 1 ∣ H 1 ) k ∑ π 0 P ( X = k ∣ H 0 ) P ( declare H 0 ∣ X = k ) + π 1 P ( X = k ∣ H 1 ) P ( declare H 1 ∣ X = k )
, therefore,
i declare = arg max i π i P ( X = k ∣ H i ) i_{\text{declare} } = \argmax_i \;\pi_i P(X=k|H_i)
i declare = i arg max π i P ( X = k ∣ H i )
So MAP decision rule is the one that minimizes p e p_e p e minimum .
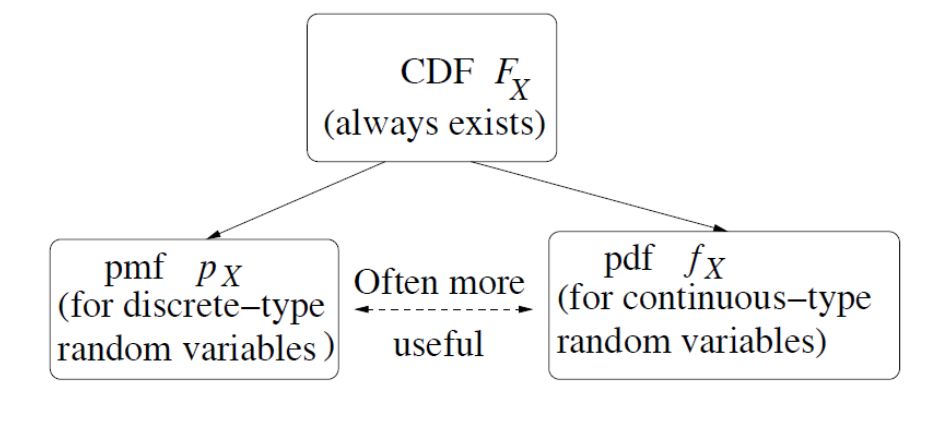
cdf
what to do if Ω \Omega Ω
the usual event algebra in this case if the Borel algebra.
it is the smallest algebra closed under formation of countably many unions and intersections containing all finite intervals in R \mathbb{R} R
ϵ = ( R , B , P ) \epsilon = (\mathbb{R}, \mathcal{B}, P)
ϵ = ( R , B , P )
F X ( C ) = Pr ( X ≤ C ) F_X(C) = \operatorname{Pr}(X\le C)
F X ( C ) = Pr ( X ≤ C )
$F_X d e t e r m i n e s p r o b a b i l i t y m e a s u r e o n s e m i − i n f i n i t e i n t e r v a l s determines probability measure on semi-infinite intervals d e t er min es p ro babi l i t y m e a s u reo n se mi − in f ini t e in t er v a l s
Size of jump points of cdf:
Δ F X ( x ) = F X ( c ) − F X ( c − ) \Delta F_X(x) = F_X(c) -F_X(c-)
Δ F X ( x ) = F X ( c ) − F X ( c − )
P ( X ∈ ( a , b ] ) = F X ( b ) − F X ( a ) , a < b P(X \in (a,b]) = F_X(b) - F_X(a), \quad a < b
P ( X ∈ ( a , b ]) = F X ( b ) − F X ( a ) , a < b
P ( X < c ) = F X ( c − ) P(X < c) = F_X(c-)
P ( X < c ) = F X ( c − )
P ( X = c ) = Δ F X ( c ) P(X = c) = \Delta F_X(c)
P ( X = c ) = Δ F X ( c )
pdf
1 = ∫ − ∞ + ∞ f X ( u ) d u 1 = \int_{-\infty}^{+\infty}f_X(u)du
1 = ∫ − ∞ + ∞ f X ( u ) d u
E [ X ] = ∫ − ∞ ∞ u f X ( u ) d u E[X] = \int_{-\infty }^{\infty }u f_X(u)du
E [ X ] = ∫ − ∞ ∞ u f X ( u ) d u
E [ X 2 ] = ∫ − ∞ ∞ u 2 f X ( u ) d u E[X^2] = \int_{-\infty }^{\infty }u^2 f_X(u)du
E [ X 2 ] = ∫ − ∞ ∞ u 2 f X ( u ) d u
Var ( X ) = E [ X 2 ] − E [ X ] \operatorname{Var}(X) = E[X^2] - E[X]
Var ( X ) = E [ X 2 ] − E [ X ]
if continuous at c c c
F X ′ ( c ) = f X ( c ) F_X'(c) = f_X(c)
F X ′ ( c ) = f X ( c )
The Exponential Distribution
cdf
F X ( t ) = { 1 − e − λ t t ≥ 0 0 t < 0 F_{X}(t)=\left\{\begin{array}{ll}1-e^{-\lambda t} & t \geq 0 \\0 & t<0\end{array}\right.
F X ( t ) = { 1 − e − λ t 0 t ≥ 0 t < 0
pdf
f X ( t ) = { λ e − λ t t ≥ 0 0 t < 0 f_{X}(t)=\left\{\begin{array}{l}\lambda e^{-\lambda t} \quad t \geq 0 \\0 \quad t<0\end{array}\right.
f X ( t ) = { λ e − λ t t ≥ 0 0 t < 0
E [ X ] = 1 λ E [ X n ] = n ! λ n E[X] = \frac{1}{\lambda} \\ E[X^n] = \frac{n!}{\lambda^n}
E [ X ] = λ 1 E [ X n ] = λ n n !
V a r ( X ) = 1 λ 2 Var(X) = \frac{1}{\lambda^2}
Va r ( X ) = λ 2 1
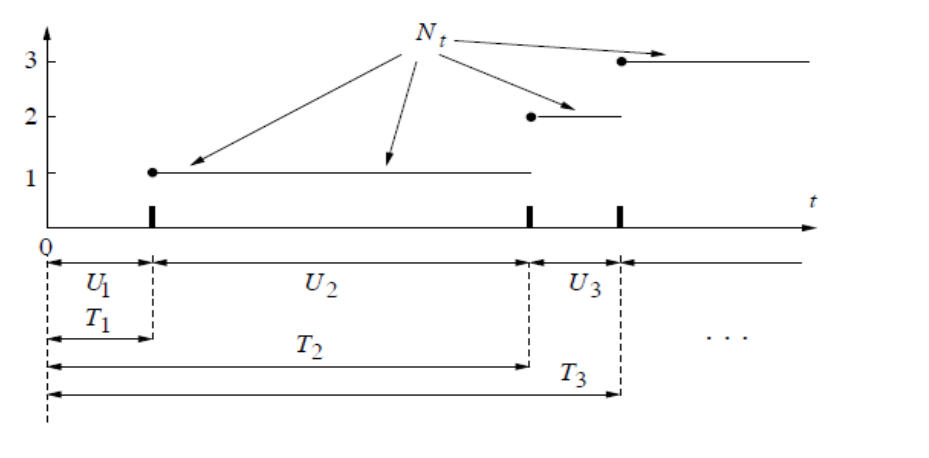
The Poisson process
泊松过程 - 维基百科,自由的百科全书
Different distribution in one graph
N t N_t N t
P { N t = k } = [ λ t ] k k ! e − λ t P\left\{N_{t}=k\right\}=\frac{[\lambda t]^{k}}{k !} e^{-\lambda t}
P { N t = k } = k ! [ λ t ] k e − λ t
U i U_i U i
have Exponential Distributions
f U i ( t ) = { λ e − λ t t ≥ 0 0 t < 0 f_{U_{i}}(t)=\left\{\begin{array}{l}\lambda e^{-\lambda t} \quad t \geq 0 \\0 \quad t<0\end{array}\right.
f U i ( t ) = { λ e − λ t t ≥ 0 0 t < 0
T k T_k T k
T r = ∑ i = 1 r U i T_r = \sum_{i=1}^r U_i
T r = i = 1 ∑ r U i
have Erlang Distributions
The Erlang Distribution
In a Poisson process with arrival rate λ \lambda λ k k k
f ( x ; k , λ ) = λ k x k − 1 e − λ x ( k − 1 ) ! for x , λ ≥ 0 f(x; k,\lambda)={\lambda^k x^{k-1} e^{-\lambda x} \over (k-1)!}\quad{\text{for }}x, \lambda \geq 0
f ( x ; k , λ ) = ( k − 1 )! λ k x k − 1 e − λ x for x , λ ≥ 0
Linear Scaling of pdfs
Y = a X + b Y = aX+b
Y = a X + b
is a linear transformation of X X X
cdf:
F Y ( y ) = F X ( y − b a ) F_Y(y) = F_X(\frac{y-b}{a} )
F Y ( y ) = F X ( a y − b )
pdf
f Y ( y ) = d F Y ( y ) d y = 1 a f X ( y − b a ) f_Y(y) = \frac{dF_Y(y)}{dy} = \frac{1}{a}f_X(\frac{y-b}{a} )
f Y ( y ) = d y d F Y ( y ) = a 1 f X ( a y − b )
X ∼ U [ a , b ] V a r ( X ) = 1 12 ( b − a ) 2 E [ X ] = a + b 2 X \sim \mathcal{U}_{[a,b]} \\ Var(X) = \frac{1}{12}(b-a)^2 \\ E[X] = \frac{a+b}{2}
X ∼ U [ a , b ] Va r ( X ) = 12 1 ( b − a ) 2 E [ X ] = 2 a + b
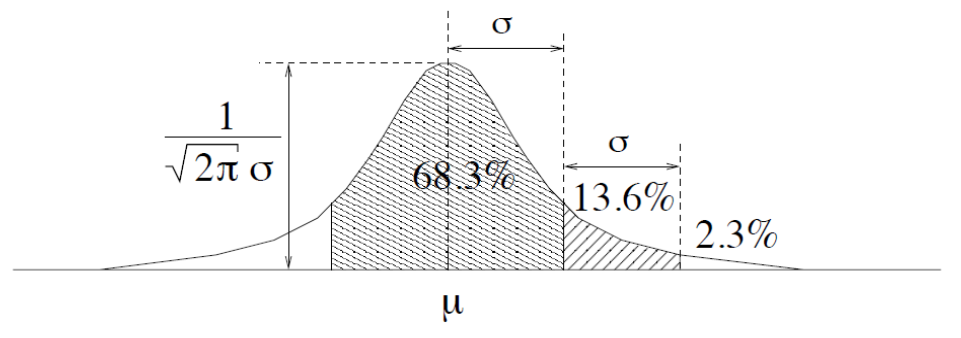
The Gaussian (Normal) Distribution
N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 )
f ( x ) = 1 2 π σ 2 exp ( − ( x − μ ) 2 2 σ 2 ) f(x)=\frac{1}{\sqrt{2 \pi \sigma^{2}}} \exp \left(-\frac{(x-\mu)^{2}}{2 \sigma^{2}}\right)
f ( x ) = 2 π σ 2 1 exp ( − 2 σ 2 ( x − μ ) 2 )
pdf
f ( x ) = 1 2 π exp ( − x 2 2 ) f(x) = \frac{1}{\sqrt{2\pi}}\exp\left(-\frac{x^2}{2}\right)
f ( x ) = 2 π 1 exp ( − 2 x 2 )
cdf
Φ ( x ) = 1 2 π ∫ − ∞ x exp ( − u 2 2 ) d u \Phi(x) = \frac{1}{\sqrt{2\pi}} \int_{-\infty}^{x}\exp\left(-\frac{u^2}{2}\right) du
Φ ( x ) = 2 π 1 ∫ − ∞ x exp ( − 2 u 2 ) d u
Q ( x ) = P ( S > x ) = 1 − Φ ( x ) Q(x) = P(S>x)=1-\Phi(x)
Q ( x ) = P ( S > x ) = 1 − Φ ( x )
$N(\mu,\sigma^2) c a n b e o b t a i n e d f r o m t h e s t a n d a r d d i s t r i b u t i o n can be obtained from the standard distribution c anb eo b t ain e df ro m t h es t an d a r dd i s t r ib u t i o n
E [ Y ] = E [ σ X + μ ] = μ E[Y] = E[\sigma X+\mu] = \mu
E [ Y ] = E [ σ X + μ ] = μ
V a r ( Y ) = V a r ( σ X + μ ) = σ 2 Var(Y) = Var(\sigma X+\mu) = \sigma^2
Va r ( Y ) = Va r ( σ X + μ ) = σ 2
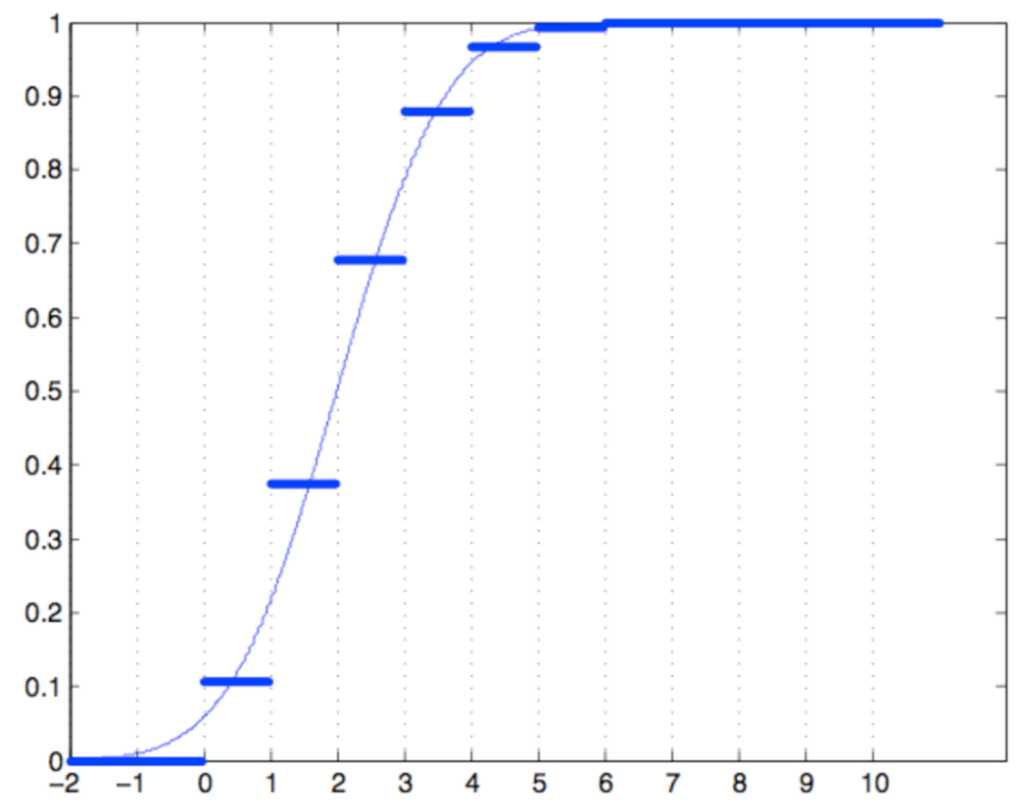
The Central Limit Theorem
Let S n , p ∼ Bin ( n , p ) S_{n,p} \sim \operatorname{Bin}(n,p) S n , p ∼ Bin ( n , p )
S ^ n , p : = S n , p − μ σ \hat S_{n,p} := \frac{S_{n,p} - \mu}{\sigma}
S ^ n , p := σ S n , p − μ
then
lim n → ∞ P { S ^ n , p ≤ c } = Φ ( c ) \lim _{n \rightarrow \infty} P\left\{\hat{S}_{n, p} \leq c\right\}=\Phi(c)
n → ∞ lim P { S ^ n , p ≤ c } = Φ ( c )
The Central Limit Thm Continuity Correction
when bounded from above
P { S n , p ≤ L } → P { S n , p − 1 2 ≤ L } = P { S n , p − μ − 1 2 σ ≤ L − μ σ } = P { S ^ n , p ≤ L − μ + 1 2 σ } ≈ Φ ( L − μ + 1 2 σ ) . \begin{aligned}
P\left\{S_{n, p} \leq L\right\} \rightarrow
&P\left\{S_{n, p}-\frac{1}{2} \leq L\right\} \\
=&P\left\{\frac{S_{n, p}-\mu-\frac{1}{2}}{\sigma} \leq \frac{L-\mu}{\sigma}\right\} \\
=&P\left\{\hat{S}_{n, p} \leq \frac{L-\mu+\frac{1}{2}}{\sigma}\right\} \\
\approx &\Phi\left(\frac{L-\mu+\frac{1}{2}}{\sigma}\right) .
\end{aligned}
P { S n , p ≤ L } → = = ≈ P { S n , p − 2 1 ≤ L } P { σ S n , p − μ − 2 1 ≤ σ L − μ } P { S ^ n , p ≤ σ L − μ + 2 1 } Φ ( σ L − μ + 2 1 ) .
when bounded from below
P { S n , p ≥ L } → P { S n , p + 1 2 ≥ L } P\left\{S_{n, p} \geq L\right\} \rightarrow
P\left\{S_{n, p}+\frac{1}{2} \geq L\right\}
P { S n , p ≥ L } → P { S n , p + 2 1 ≥ L }
Generating a r.v. with a specified distribution
$U i s r . v . ∗ ∗ u n i f o r m l y ∗ ∗ d i s t r i b u t e d o n is r.v. **uniformly** distributed on i sr . v . ∗ ∗ u ni f or m l y ∗ ∗ d i s t r ib u t e d o n , f i n d , find , f in d s u c h t h a t such that s u c h t ha t h a s a d i s t r i b u t i o n has a distribution ha s a d i s t r ib u t i o n
Let g ( u ) = F − 1 ( u ) g(u) = F^{-1}(u) g ( u ) = F − 1 ( u )
then let X = g ( U ) X=g(U) X = g ( U )
F X ( g ( u ) ) = F U ( u ) = u F_X(g(u))=F_U(u)=u
F X ( g ( u )) = F U ( u ) = u
suffices.
Failure Rate Functions
For r.v. T T T
h ( t ) = lim ϵ → 0 P { t < T < t + ϵ ∣ T > t } ϵ h(t) = \lim_{\epsilon \to 0}\frac{P\{t<T<t + \epsilon |T>t\}}{\epsilon }
h ( t ) = ϵ → 0 lim ϵ P { t < T < t + ϵ ∣ T > t }
then, given that the system is not failed up to time t t t ϵ \epsilon ϵ
T ∈ ( t , t + ϵ ) ∼ h ( t ) ϵ T \in (t,t+\epsilon ) \sim h(t)\epsilon
T ∈ ( t , t + ϵ ) ∼ h ( t ) ϵ
the h ( t ) h(t) h ( t )
h ( t ) : = lim ϵ → 0 P { t < T < t + ϵ ∣ T > t } ϵ = lim ϵ → 0 P { t < T < t + ϵ } ϵ P { T > t } = lim ϵ → 0 F T ( t + ϵ ) − F T ( t ) ϵ ( 1 − F T ( t ) ) = F T ′ ( t ) 1 − F T ( t ) = f T ( t ) 1 − F T ( t ) . \begin{aligned}h(t):=\lim _{\epsilon \rightarrow 0} \frac{P\{t<T<t+\epsilon \mid T>t\}}{\epsilon} & =\lim _{\epsilon \rightarrow 0} \frac{P\{t<T<t+\epsilon\}}{\epsilon P\{T>t\}} \\& =\lim _{\epsilon \rightarrow 0} \frac{F_{T}(t+\epsilon)-F_{T}(t)}{\epsilon\left(1-F_{T}(t)\right)} \\& =\frac{F_{T}^{\prime}(t)}{1-F_{T}(t)}=\frac{f_{T}(t)}{1-F_{T}(t)} .\end{aligned}
h ( t ) := ϵ → 0 lim ϵ P { t < T < t + ϵ ∣ T > t } = ϵ → 0 lim ϵ P { T > t } P { t < T < t + ϵ } = ϵ → 0 lim ϵ ( 1 − F T ( t ) ) F T ( t + ϵ ) − F T ( t ) = 1 − F T ( t ) F T ′ ( t ) = 1 − F T ( t ) f T ( t ) .
notice that
− h ( t ) = [ ln ( 1 − F T ( t ) ) ] ′ − ∫ 0 t h ( t ) d t = ln ( 1 − F T ( t ) ) − ln ( 1 − F T ( 0 ) ) = ln ( 1 − F T ( t ) ) therefore, F T ( t ) = 1 − exp ( − ∫ 0 t h ( t ) d t ) . -h(t)=[\ln(1-F_T(t))]' \\ -\int_0^th(t)dt=\ln(1-F_T(t))-\ln(1-F_T(0))=\ln(1-F_T(t))
\\ \text{therefore, } F_T(t) = 1-\exp\left(-\int_0^t h(t) dt\right).
− h ( t ) = [ ln ( 1 − F T ( t )) ] ′ − ∫ 0 t h ( t ) d t = ln ( 1 − F T ( t )) − ln ( 1 − F T ( 0 )) = ln ( 1 − F T ( t )) therefore, F T ( t ) = 1 − exp ( − ∫ 0 t h ( t ) d t ) .
Hypothesis Testing see also: Binary hypothesis testing with discrete-type observations
A random variable X X X f 1 f_1 f 1 H 1 H_1 H 1 f 0 f_0 f 0 H 0 H_0 H 0
For observation u u u
Λ ( u ) = f 1 ( u ) f 0 ( u ) \Lambda(u) = \frac{f_1(u)}{f_0(u)}
Λ ( u ) = f 0 ( u ) f 1 ( u )
ML rule
{ Λ ( u ) > 1 declare H 1 Λ ( u ) < 1 declare H 0 \begin{cases}\Lambda(u) > 1 & \text{declare } H_1 \\\Lambda(u) < 1 & \text{declare } H_0\\\end{cases}
{ Λ ( u ) > 1 Λ ( u ) < 1 declare H 1 declare H 0
MAP rule
with prior probabilities π 0 \pi_0 π 0 π 1 \pi_1 π 1
{ Λ ( u ) > π 0 π 1 declare H 1 Λ ( u ) < π 0 π 1 declare H 0 \begin{cases}\Lambda(u) > \frac{\pi_0}{\pi_1} & \text{declare } H_1 \\\Lambda(u) < \frac{\pi_0}{\pi_1} & \text{declare } H_0\\\end{cases}
{ Λ ( u ) > π 1 π 0 Λ ( u ) < π 1 π 0 declare H 1 declare H 0
error
p e = P ( Declare H 1 ∣ H 0 ) π 0 + P ( Declare H 1 ∣ H 1 ) π 1 p_{e}=P\left(\text { Declare } H_{1} \mid H_{0}\right) \pi_{0}+P\left(\text { Declare } H_{1} \mid H_{1}\right) \pi_{1}
p e = P ( Declare H 1 ∣ H 0 ) π 0 + P ( Declare H 1 ∣ H 1 ) π 1
Jointly Distributed Random Variables joint CDF
F X Y ( u , v ) = P { X ≤ u , Y ≤ v } . F_{XY}(u, v) = P\{X\le u, Y\le v\}.
F X Y ( u , v ) = P { X ≤ u , Y ≤ v } .
P { ( X , Y ) ∈ ( a , b ] × ( c , d ] } = F X , Y ( b , d ) − F X , Y ( a , d ) − F X , Y ( b , c ) + F X , Y ( a , c ) . P\{(X, Y) \in (a,b]\times (c,d]\}=F_{X, Y}(b, d)-F_{X, Y}(a, d)-F_{X, Y}(b, c)+F_{X, Y}(a, c) .
P {( X , Y ) ∈ ( a , b ] × ( c , d ]} = F X , Y ( b , d ) − F X , Y ( a , d ) − F X , Y ( b , c ) + F X , Y ( a , c ) .
Is a functon valid joint CDF?
To be a valid joint CDF for two random variables U U U V V V
Non-decreasing : F ( u , v ) F(u, v) F ( u , v ) u u u v v v u 1 ≤ u 2 u_1 \leq u_2 u 1 ≤ u 2 v 1 ≤ v 2 v_1 \leq v_2 v 1 ≤ v 2 F ( u 1 , v 1 ) ≤ F ( u 2 , v 2 ) F(u_1, v_1) \leq F(u_2, v_2) F ( u 1 , v 1 ) ≤ F ( u 2 , v 2 )
Right-continuous : F ( u , v ) F(u, v) F ( u , v ) u u u v v v
Limits at infinity :
lim u → − ∞ F ( u , v ) = 0 \lim_{u \to -\infty} F(u, v) = 0 lim u → − ∞ F ( u , v ) = 0 v v v lim v → − ∞ F ( u , v ) = 0 \lim_{v \to -\infty} F(u, v) = 0 lim v → − ∞ F ( u , v ) = 0 u u u lim u → ∞ F ( u , v ) = F ( ∞ , v ) \lim_{u \to \infty} F(u, v) = F(\infty, v) lim u → ∞ F ( u , v ) = F ( ∞ , v ) v v v lim v → ∞ F ( u , v ) = F ( u , ∞ ) \lim_{v \to \infty} F(u, v) = F(u, \infty) lim v → ∞ F ( u , v ) = F ( u , ∞ ) u u u lim u → ∞ , v → ∞ F ( u , v ) = 1 \lim_{u \to \infty, v \to \infty} F(u, v) = 1 lim u → ∞ , v → ∞ F ( u , v ) = 1
Non-negativity : F ( u , v ) ≥ 0 F(u, v) \geq 0 F ( u , v ) ≥ 0 u , v u, v u , v
Joint Probability : For any u 1 < u 2 u_1 < u_2 u 1 < u 2 v 1 < v 2 v_1 < v_2 v 1 < v 2 F ( u 2 , v 2 ) − F ( u 2 , v 1 ) − F ( u 1 , v 2 ) + F ( u 1 , v 1 ) ≥ 0 F(u_2, v_2) - F(u_2, v_1) - F(u_1, v_2) + F(u_1, v_1) \geq 0 F ( u 2 , v 2 ) − F ( u 2 , v 1 ) − F ( u 1 , v 2 ) + F ( u 1 , v 1 ) ≥ 0
Joint PMF
p X Y ( x , y ) = { X = x , Y = y } p_{XY}(x,y) = \{X=x, Y=y\}
p X Y ( x , y ) = { X = x , Y = y }
Marginal pdf
f X ( x ) = ∫ − ∞ ∞ f X Y ( x , y ) d y f_X(x)=\int_{-\infty}^{\infty}f_{XY}(x,y)dy
f X ( x ) = ∫ − ∞ ∞ f X Y ( x , y ) d y
The Marginal cdfs F X ( u ) = lim n → ∞ F X , Y ( u , n ) and F Y ( v ) = lim n → ∞ F X , Y ( n , v ) F_{X}(u)=\lim _{n \rightarrow \infty} F_{X, Y}(u, n) \quad \text { and } \quad F_{Y}(v)=\lim _{n \rightarrow \infty} F_{X, Y}(n, v)
F X ( u ) = n → ∞ lim F X , Y ( u , n ) and F Y ( v ) = n → ∞ lim F X , Y ( n , v )
The Conditional pdf
f Y ∣ X ( v ∣ u ) = { f X Y ( u , v ) f X ( u ) if f X ( u ) ≠ 0 undefined if f X ( u ) = 0 f_{Y|X}(v|u) = \begin{cases}\frac{f_{XY}(u,v)}{f_X(u)} & \text{if} f_X(u)\ne 0
\\\text{undefined} & \text{if} f_X(u) = 0 \\\end{cases}
f Y ∣ X ( v ∣ u ) = { f X ( u ) f X Y ( u , v ) undefined if f X ( u ) = 0 if f X ( u ) = 0
E [ Y ∣ X = u ] = ∫ − ∞ ∞ y f Y ∣ X ( y ∣ x ) d y E[Y|X=u] = \int_{-\infty}^{\infty}yf_{Y|X}(y|x)dy
E [ Y ∣ X = u ] = ∫ − ∞ ∞ y f Y ∣ X ( y ∣ x ) d y
Sum or r.v
given Z = X + Y Z = X + Y Z = X + Y
E [ Z ] = E [ X ] + E [ Y ] E[Z]=E[X]+E[Y]
E [ Z ] = E [ X ] + E [ Y ]
V a r ( Z ) = V a r ( X ) + V a r ( Y ) + 2 C o v ( X , Y ) V a r ( X − Y ) = V a r ( X ) + V a r ( Y ) − 2 C o v ( X , Y ) Var(Z) = Var(X) + Var(Y) + 2 Cov(X, Y) \\ Var(X-Y) = Var(X) + Var(Y) - 2 Cov(X, Y) \\
Va r ( Z ) = Va r ( X ) + Va r ( Y ) + 2 C o v ( X , Y ) Va r ( X − Y ) = Va r ( X ) + Va r ( Y ) − 2 C o v ( X , Y )
C o v ( X , Y ) = E [ ( X − E [ X ] ) ( Y − E [ Y ] ) ] Cov(X,Y)=E[(X−E[X])(Y−E[Y])]
C o v ( X , Y ) = E [( X − E [ X ]) ( Y − E [ Y ])]
If X and Y are independent, then C o v ( X , Y ) = 0 Cov(X, Y) = 0 C o v ( X , Y ) = 0
p Z ( u ) = p X ( u ) ∗ p Y ( u ) p Z ( u ) = ∑ k = − ∞ ∞ p X ( k ) p Y ( u − k ) = ∑ k = − ∞ ∞ p X ( u − k ) p Y ( k ) \begin{array}{c}p_{Z}(u)=p_{X}(u) * p_{Y}(u) \\p_{Z}(u)=\sum_{k=-\infty}^{\infty} p_{X}(k) p_{Y}(u-k)=\sum_{k=-\infty}^{\infty} p_{X}(u-k) p_{Y} (k) \\\end{array}
p Z ( u ) = p X ( u ) ∗ p Y ( u ) p Z ( u ) = ∑ k = − ∞ ∞ p X ( k ) p Y ( u − k ) = ∑ k = − ∞ ∞ p X ( u − k ) p Y ( k )
f Z ( u ) = f X ( u ) ∗ f Y ( u ) f Z ( u ) = ∫ − ∞ ∞ f X ( τ ) f Y ( u − τ ) d τ = ∫ − ∞ ∞ f X ( u − τ ) f Y ( τ ) d τ
\begin{array}{c}f_{Z}(u)=f_{X}(u) * f_{Y}(u) \\f_{Z}(u)=\int_{-\infty}^{\infty} f_{X}(\tau) f_{Y}(u-\tau) d \tau=\int_{-\infty}^{\infty} f_{X}(u-\tau) f_{Y}(\tau) d \tau\end{array}
f Z ( u ) = f X ( u ) ∗ f Y ( u ) f Z ( u ) = ∫ − ∞ ∞ f X ( τ ) f Y ( u − τ ) d τ = ∫ − ∞ ∞ f X ( u − τ ) f Y ( τ ) d τ
( X , Y ) ↦ ( W , Z ) where W = a X + b Y Z = c X + d Y (X, Y) \mapsto(W, Z) \quad \text { where } \quad
\begin{array}{c}
W = aX+b Y \\
Z = c X+d Y
\end{array}
( X , Y ) ↦ ( W , Z ) where W = a X + bY Z = c X + d Y
( W Z ) = A ( X Y ) where Z = ( a b c d ) \begin{pmatrix}
W \\ Z
\end{pmatrix}
=
A
\begin{pmatrix}
X \\ Y
\end{pmatrix}
\quad \text{where} \quad
Z = \begin{pmatrix}
a & b \\ c & d
\end{pmatrix}
( W Z ) = A ( X Y ) where Z = ( a c b d )
Proposition
f W Z ( w , z ) = 1 ∣ det A ∣ f X Y ( A − 1 ( w z ) ) f_{W Z}(w, z)=\frac{1}{|\operatorname{det} A|} f_{X Y}\left(A^{-1}\left(\begin{array}{c}
w \\
z
\end{array}\right)\right)
f W Z ( w , z ) = ∣ det A ∣ 1 f X Y ( A − 1 ( w z ) )
Correlation and Covariance
For r.v. X X X Y Y Y
correlation
E [ X Y ] E[XY]
E [ X Y ]
covirance
C o v ( X , Y ) : = E [ ( X − E [ X ] ) ( Y − E [ Y ] ) ] Cov(X, Y) := E[(X-E[X])(Y-E[Y])]
C o v ( X , Y ) := E [( X − E [ X ]) ( Y − E [ Y ])]
C o v ( X , Y ) = E [ X Y ] − E [ X ] E [ Y ] C o v ( X , X ) = V a r ( X ) Cov(X, Y) = E[XY]- E[X]E[Y] \\
Cov(X, X) = Var(X)
C o v ( X , Y ) = E [ X Y ] − E [ X ] E [ Y ] C o v ( X , X ) = Va r ( X )
correlation coeffcient
ρ X Y = Cov ( X , Y ) Var ( X ) Var ( Y ) = Cov ( X , Y ) σ X σ Y \rho_{X Y}=\frac{\operatorname{Cov}(X, Y)}{\sqrt{\operatorname{Var}(X)} \sqrt{\operatorname{Var}(Y)}}=\frac{\operatorname{Cov}(X, Y)}{\sigma_X \sigma_Y}
ρ X Y = Var ( X ) Var ( Y ) Cov ( X , Y ) = σ X σ Y Cov ( X , Y )
if E [ X ] = E [ Y ] = 0 E[X] = E[Y] = 0 E [ X ] = E [ Y ] = 0
C o v ( X , Y ) = E [ X Y ] Cov(X, Y) = E[XY]
C o v ( X , Y ) = E [ X Y ]
$X , , ,
C o v ( X , Y ) = 0 Cov(X, Y) = 0
C o v ( X , Y ) = 0
$X , , ,
C o v ( X , Y ) > 0 Cov(X, Y) > 0
C o v ( X , Y ) > 0
and
C o v ( X + Y , U + V ) = C o v ( X , U ) + C o v ( X , V ) + C o v ( Y , U ) + C o v ( Y , V ) Cov(X+Y, U+V) = Cov(X, U) + Cov(X, V) + Cov(Y, U) + Cov(Y, V)
C o v ( X + Y , U + V ) = C o v ( X , U ) + C o v ( X , V ) + C o v ( Y , U ) + C o v ( Y , V )
C o v ( a X + b , c Y + d ) = a c C o v ( X , Y ) Cov(aX+b, cY+d) = acCov(X, Y)
C o v ( a X + b , c Y + d ) = a c C o v ( X , Y )
Cauchy-Schwarz Inequality
∣ E [ X Y ] ∣ ≤ E [ X 2 ] E [ Y 2 ] |E[X Y]| \leq \sqrt{E\left[X^2\right] E\left[Y^2\right]}
∣ E [ X Y ] ∣ ≤ E [ X 2 ] E [ Y 2 ]
∣ Cov ( X , Y ) ∣ ≤ Var ( X ) Var ( Y ) |\operatorname{Cov}(X, Y)| \leq \sqrt{\operatorname{Var}(X) \operatorname{Var}(Y)}
∣ Cov ( X , Y ) ∣ ≤ Var ( X ) Var ( Y )
Minimum Mean Square Error Estimation
flowchart LR
A[Experiment] -->|Y| B[Noise]
B -->|X| C[Guess]
C -->|"g(X)=Y"| ...An estimator is unbiased if
E [ T ^ ] = E [ Y ] E[\hat{T}] = E[Y]
E [ T ^ ] = E [ Y ]
Constant estimators
(Continued) To minimize MSE with Constant estimator δ \delta δ
E [ ( Y − δ ) 2 ] = E [ Y 2 ] − 2 δ E [ Y ] + δ 2 = E [ Y 2 ] − E [ Y ] 2 + E [ Y ] 2 − 2 δ E [ Y ] + δ 2 = V a r ( Y ) + ( E [ Y ] − δ ) 2 \begin{aligned}
E\left[(Y-\delta)^2\right] & = E\left[Y^2\right]-2 \delta E[Y]+\delta^2 \\ & = E[Y^2] - E[Y]^2 + E[Y]^2 - 2\delta E[Y] + \delta^2 \\ & = Var(Y) + (E[Y]-\delta)^2
\end{aligned}
E [ ( Y − δ ) 2 ] = E [ Y 2 ] − 2 δ E [ Y ] + δ 2 = E [ Y 2 ] − E [ Y ] 2 + E [ Y ] 2 − 2 δ E [ Y ] + δ 2 = Va r ( Y ) + ( E [ Y ] − δ ) 2
therefore, MSE is minimized iff δ = E [ Y ] \delta = E[Y] δ = E [ Y ] V a r ( Y ) Var(Y) Va r ( Y )
Unconstrained estimators
We wish to estimate Y Y Y observation X X X
Goal: Minimize the mean-square error (MSE )
E [ ( Y − g ( X ) ) 2 ] E[(Y-g(X))^2]
E [( Y − g ( X ) ) 2 ]
The resulting estimator g ∗ ( X ) g^*(X) g ∗ ( X ) unconstrained optimal of Y Y Y X X X g g g
For a observation X = u X=u X = u
g ∗ ( u ) = E [ Y ∣ X = u ] = ∫ − ∞ ∞ v f Y ∣ X ( v ∣ u ) d v g^*(u)=E[Y \mid X=u]=\int_{-\infty}^{\infty} v f_{Y \mid X}(v \mid u) d v
g ∗ ( u ) = E [ Y ∣ X = u ] = ∫ − ∞ ∞ v f Y ∣ X ( v ∣ u ) d v
and
M S E = E [ ( Y − E [ Y ∣ X ] ) 2 ] = E [ Y 2 ] − E [ ( E [ Y ∣ X ] ) 2 ] = E [ Y 2 ] − E [ g ∗ ( X ) 2 ] \begin{aligned}
MSE & = E[(Y-E[Y|X])^2] \\
&= E[Y^2] - E[(E[Y|X])^2] \\
&= E[Y^2] - E[g^*(X)^2]
\end{aligned}
MSE = E [( Y − E [ Y ∣ X ] ) 2 ] = E [ Y 2 ] − E [( E [ Y ∣ X ] ) 2 ] = E [ Y 2 ] − E [ g ∗ ( X ) 2 ]
Linear estimators
Because E [ Y ∣ X = u ] = ∫ − ∞ ∞ v f Y ∣ X ( v ∣ u ) d v E[Y| X=u]=\int_{-\infty}^{\infty} v f_{Y | X}(v | u) d v E [ Y ∣ X = u ] = ∫ − ∞ ∞ v f Y ∣ X ( v ∣ u ) d v
L ( X ) = a X + b L(X) = aX + b
L ( X ) = a X + b
as g ( X ) g(X) g ( X )
With a given a a a
μ Y + a ( X − μ X ) \mu_Y + a(X-\mu_X)
μ Y + a ( X − μ X )
then
M S E = E [ ( Y − μ Y − a ( X − μ X ) ) 2 ] = Var ( Y − a X ) = Cov ( Y − a X , Y − a X ) = Var ( Y ) − 2 a Cov ( Y , X ) + a 2 Var ( X ) . \begin{aligned}
M S E & =E\left[\left(Y-\mu_Y-a\left(X-\mu_X\right)\right)^2\right] \\
& =\operatorname{Var}(Y-a X) \\
& =\operatorname{Cov}(Y-a X, Y-a X) \\
& =\operatorname{Var}(Y)-2 a \operatorname{Cov}(Y, X)+a^2 \operatorname{Var}(X) .
\end{aligned}
MSE = E [ ( Y − μ Y − a ( X − μ X ) ) 2 ] = Var ( Y − a X ) = Cov ( Y − a X , Y − a X ) = Var ( Y ) − 2 a Cov ( Y , X ) + a 2 Var ( X ) .
To minimize M S E MSE MSE 0 = d d a M S E 0 = \frac{d}{da}MSE 0 = d a d MSE
a ∗ = C o v ( Y , X ) V a r ( X ) a^* = \frac{Cov(Y,X)}{Var(X)}
a ∗ = Va r ( X ) C o v ( Y , X )
i.e.
L ∗ ( X ) = μ Y + ( Cov ( Y , X ) Var ( X ) ) ( X − μ X ) = μ Y + σ Y ρ X , Y ( X − μ X σ X ) . \begin{aligned}
L^*(X)
& =\mu_Y+\left(\frac{\operatorname{Cov}(Y, X)}{\operatorname{Var}(X)}\right)\left(X-\mu_X\right) \\
& =\mu_Y+\sigma_Y \rho_{X, Y}\left(\frac{X-\mu_X}{\sigma_X}\right) .
\end{aligned}
L ∗ ( X ) = μ Y + ( Var ( X ) Cov ( Y , X ) ) ( X − μ X ) = μ Y + σ Y ρ X , Y ( σ X X − μ X ) .
and minimum MSE is
σ Y 2 − Cov ( X , Y ) 2 Var ( X ) = σ Y 2 ( 1 − ρ X , Y 2 ) \sigma_Y^2-\frac{\operatorname{Cov}(X, Y)^2}{\operatorname{Var}(X)}=\sigma_Y^2\left(1-\rho_{X, Y}^2\right)
σ Y 2 − Var ( X ) Cov ( X , Y ) 2 = σ Y 2 ( 1 − ρ X , Y 2 )
Odering
E [ ( Y − g ∗ ( X ) ) 2 ] ⏟ MSE for g ∗ ( X ) = E [ Y ∣ X ] ≤ σ Y 2 ( 1 − ρ X , Y 2 ) ⏟ MSE for L ∗ ( X ) = E ^ [ Y ∣ X ] ≤ σ Y 2 ⏟ MSE for δ ∗ = E [ Y ] . \underbrace{E\left[\left(Y-g^*(X)\right)^2\right]}_{\text {MSE for } g^*(X)=E[Y \mid X]} \leq \underbrace{\sigma_Y^2\left(1-\rho_{X, Y}^2\right)}_{\text {MSE for } L^*(X)=\widehat{E}[Y \mid X]} \leq \underbrace{\sigma_Y^2}_{\text {MSE for } \delta^*=E[Y] .}
MSE for g ∗ ( X ) = E [ Y ∣ X ] E [ ( Y − g ∗ ( X ) ) 2 ] ≤ MSE for L ∗ ( X ) = E [ Y ∣ X ] σ Y 2 ( 1 − ρ X , Y 2 ) ≤ MSE for δ ∗ = E [ Y ] . σ Y 2
for joint Gaussian, g ∗ ( X ) = L ∗ ( X ) g^*(X)=L^*(X) g ∗ ( X ) = L ∗ ( X )
Law of Large Numbers
recall Chebyshev’s Inequality
Let X 1 , X 2 , ⋯ X n X_1, X_2, \cdots X_n X 1 , X 2 , ⋯ X n μ \mu μ V a r ( X ) = σ 2 Var(X)=\sigma^2 Va r ( X ) = σ 2
X n ‾ = 1 n ∑ k = 1 n X k \overline{X_n} = \frac{1}{n} \sum_{k=1}^{n} X_k
X n = n 1 k = 1 ∑ n X k
Law of Large Numbers
for any s > 0 s>0 s > 0
P { ∣ X n ‾ − μ ∣ ≥ s } ≤ σ 2 n s 2 → 0 P\left\{ |\overline{X_n} - \mu| \ge s \right\} \le \frac{\sigma^2}{ns^2} \to 0
P { ∣ X n − μ ∣ ≥ s } ≤ n s 2 σ 2 → 0
Central Limit Theorem
Let
Z n = X n ‾ − μ σ n Z_n=\frac{\overline{X_n}-\mu}{\frac{\sigma}{\sqrt{n}}}
Z n = n σ X n − μ
then E [ Z n ] = 0 E[Z_n] = 0 E [ Z n ] = 0 V a r ( Z ) = 1 Var(Z) = 1 Va r ( Z ) = 1 Z n Z_n Z n
lim n → ∞ F Z n ( c ) = Φ ( c ) \lim_{n\to \infty} F_{Z_n} (c) = \Phi(c)
n → ∞ lim F Z n ( c ) = Φ ( c )
The Central Limit Theorem Continuity Correction
Replace ∑ i = 1 n X i → ∑ i = 1 n X i − 1 2 \sum_{i=1}^n X_i \rightarrow \sum_{i=1}^n X_i-\frac{1}{2} ∑ i = 1 n X i → ∑ i = 1 n X i − 2 1
Replace ∑ i = 1 n X i → ∑ i = 1 n X i + 1 2 \sum_{i=1}^n X_i \rightarrow \sum_{i=1}^n X_i+\frac{1}{2} ∑ i = 1 n X i → ∑ i = 1 n X i + 2 1
P { ∑ i = 1 n X i ≤ L } → P { ∑ i = 1 n X i − 1 2 ≤ L } = P { Z n ≤ L − n μ + 1 2 n σ } ≈ Φ ( L − n μ + 1 2 n σ ) P\left\{\sum_{i=1}^n X_i \leq L\right\} \to P\left\{\sum_{i=1}^n X_i-\frac{1}{2} \leq L\right\}
\\=P\left\{Z_n \leq \frac{L-n \mu+\frac{1}{2}}{\sqrt{n} \sigma}\right\}
\approx \Phi\left(\frac{L-n \mu+\frac{1}{2}}{\sqrt{n} \sigma}\right)
P { i = 1 ∑ n X i ≤ L } → P { i = 1 ∑ n X i − 2 1 ≤ L } = P { Z n ≤ n σ L − n μ + 2 1 } ≈ Φ ( n σ L − n μ + 2 1 )
P { ∑ i = 1 n X i ≥ L } → P { ∑ i = 1 n X i + 1 2 ≥ L } = P { Z n ≥ L − n μ − 1 2 n σ } ≈ 1 − Φ ( L − n μ − 1 2 n σ ) P\left\{\sum_{i=1}^n X_i \geq L\right\} \to P\left\{\sum_{i=1}^n X_i+\frac{1}{2} \geq L\right\}
\\=P\left\{Z_n \geq \frac{L-n \mu-\frac{1}{2}}{\sqrt{n} \sigma}\right\}
\approx 1 - \Phi\left(\frac{L-n \mu-\frac{1}{2}}{\sqrt{n} \sigma}\right)
P { i = 1 ∑ n X i ≥ L } → P { i = 1 ∑ n X i + 2 1 ≥ L } = P { Z n ≥ n σ L − n μ − 2 1 } ≈ 1 − Φ ( n σ L − n μ − 2 1 )
Joint Gaussian Random Variables
sum of Joint Gaussian Random Variables are also Gaussian Random Variables.
f W Z ( w , z ) = f W ( w ) f Z ( z ) = 1 2 π exp ( − w 2 + z 2 2 ) f_{W Z}(w, z)=f_W(w) f_Z(z)=\frac{1}{2 \pi} \exp \left(-\frac{w ^2+z^2}{2}\right)
f W Z ( w , z ) = f W ( w ) f Z ( z ) = 2 π 1 exp ( − 2 w 2 + z 2 )
( W , Z ) ↦ ( X , Y ) ( X Y ) = A ( W Z ) + b where A = ( a b c d ) (W,Z) \mapsto (X, Y) \\
\begin{pmatrix} X \\ Y \end{pmatrix}
= A \begin{pmatrix} W \\ Z \end{pmatrix}+\bold{b} \quad \text{where}\; A=
\begin{pmatrix}
a & b\\
c & d
\end{pmatrix}
( W , Z ) ↦ ( X , Y ) ( X Y ) = A ( W Z ) + b where A = ( a c b d )
( W Z ) = A − 1 ( X Y ) where A − 1 = 1 det A ( d − b − c a ) \begin{pmatrix} W \\ Z \end{pmatrix}
= A^{-1} \begin{pmatrix} X \\ Y \end{pmatrix} \quad \text{where}\; A^{-1}=
\frac{1}{\det{A}}
\begin{pmatrix}
d & -b\\
-c & a
\end{pmatrix}
( W Z ) = A − 1 ( X Y ) where A − 1 = det A 1 ( d − c − b a )
Proposition: If A A A
f X Y ( x , y ) = 1 ∣ det A ∣ f W Z ( A − 1 ( x y ) ) . f_{X Y}(x, y)=\frac{1}{|\det A|} f_{W Z}\left(A^{-1}\left(\begin{array}{l}
x \\
y
\end{array}\right)\right) .
f X Y ( x , y ) = ∣ det A ∣ 1 f W Z ( A − 1 ( x y ) ) .
Let σ X > 0 , σ Y > 0 , μ X , μ Y , − 1 < ρ < 1 \sigma_X > 0,\, \sigma_Y > 0,\, \mu_X,\, \mu_Y,\, -1<\rho<1 σ X > 0 , σ Y > 0 , μ X , μ Y , − 1 < ρ < 1
A = ( σ X ( 1 + ρ ) / 2 − σ X ( 1 − ρ ) / 2 σ Y ( 1 + ρ ) / 2 σ Y ( 1 − ρ ) / 2 ) b = ( μ X μ Y ) A=\left(\begin{array}{cc}
\sigma_X \sqrt{(1+\rho) / 2} & -\sigma_X \sqrt{(1-\rho) / 2} \\
\sigma_Y \sqrt{(1+\rho) / 2} & \sigma_Y \sqrt{(1-\rho) / 2}
\end{array}\right) \quad b=\left(\begin{array}{c}
\mu_X \\
\mu_Y
\end{array}\right)
A = ( σ X ( 1 + ρ ) /2 σ Y ( 1 + ρ ) /2 − σ X ( 1 − ρ ) /2 σ Y ( 1 − ρ ) /2 ) b = ( μ X μ Y )
then ( W Z ) → ( X Y ) = A ( W Z ) + b
\left(\begin{array}{c}
W \\
Z
\end{array}\right) \rightarrow\left(\begin{array}{l}
X \\
Y
\end{array}\right)=A\left(\begin{array}{c}
W \\
Z
\end{array}\right)+b ( W Z ) → ( X Y ) = A ( W Z ) + b bivariate Gaussian pdf:
f X Y ( x , y ) = 1 2 π σ X σ Y 1 − ρ 2 exp − ( x − μ X σ X ) 2 + ( y − μ Y σ Y ) 2 − 2 ρ ( x − μ X σ X ) ( y − μ Y σ Y ) 2 ( 1 − ρ 2 ) f_{X Y}(x, y)=\frac{1}{2 \pi \sigma_X \sigma_Y \sqrt{1-\rho^2}} \exp{-\frac{\left(\frac{x-\mu_X}{\sigma_X}\right)^2+\left(\frac{y-\mu_Y}{\sigma_Y}\right)^2-2 \rho\left(\frac{x-\mu_X}{\sigma_X}\right)\left(\frac{y-\mu_Y}{\sigma_Y}\right)}{2\left(1-\rho^2\right)}}
f X Y ( x , y ) = 2 π σ X σ Y 1 − ρ 2 1 exp − 2 ( 1 − ρ 2 ) ( σ X x − μ X ) 2 + ( σ Y y − μ Y ) 2 − 2 ρ ( σ X x − μ X ) ( σ Y y − μ Y )
Or, with normalized x ~ = x − μ x σ x , y ~ = y − μ y σ y \tilde{x} = \frac{x-\mu_x}{\sigma_x},\; \tilde{y} = \frac{y-\mu_y}{\sigma_y} x ~ = σ x x − μ x , y ~ = σ y y − μ y
f X Y ( x , y ) = 1 2 π σ X σ Y 1 − ρ 2 exp − ( y ~ − ρ x ~ ) 2 2 ( 1 − ρ 2 ) exp − x 2 2 f_{X Y}(x, y)=\frac{1}{2 \pi \sigma_X \sigma_Y \sqrt{1-\rho^2}} \exp{-\frac{(\tilde{y}-\rho \tilde{x})^2}{2\left(1-\rho^2\right)}} \exp -\frac{x^2}{2}
f X Y ( x , y ) = 2 π σ X σ Y 1 − ρ 2 1 exp − 2 ( 1 − ρ 2 ) ( y ~ − ρ x ~ ) 2 exp − 2 x 2
Properties
f X ( x ) = ∫ − ∞ + ∞ d y f X Y ( x , y ) = 1 2 π σ x 2 exp ( − ( x − μ x ) 2 2 σ x 2 ) f_X(x) = \int_{-\infty}^{+\infty} dyf_{XY}(x, y)
\\=\frac{1}{\sqrt{2 \pi \sigma_x^{2}}} \exp \left(-\frac{(x-\mu_x)^{2}}{2 \sigma_x^{2}}\right)
f X ( x ) = ∫ − ∞ + ∞ d y f X Y ( x , y ) = 2 π σ x 2 1 exp ( − 2 σ x 2 ( x − μ x ) 2 )
f Y ∣ X ( y ∣ x ) = 1 2 π σ Y 1 − ρ 2 exp − 1 2 ( y − μ Y − ρ σ Y ( x − μ X ) / σ X ) 2 σ Y 2 ( 1 − ρ 2 ) = N ( μ Y + ρ σ Y ( x − μ X σ X ) , σ Y 2 ( 1 − ρ 2 ) ) = N ( E [ Y ∣ X = x ] , V a r ( Y ∣ X = x ) ) f_{Y \mid X}(y \mid x)=\frac{1}{\sqrt{2 \pi} \sigma_Y \sqrt{1-\rho^2}} \exp{-\frac{1}{2} \frac{\left(y-\mu_Y-\rho \sigma_Y\left(x-\mu_X\right) / \sigma_X\right)^2}{\sigma_Y^2\left(1-\rho^2\right)}}
\\ =N\left(\mu_Y+\rho \sigma_Y\left(\frac{x-\mu_X}{\sigma_X}\right), \sigma_Y^2\left(1-\rho^2\right)\right)
\\ = N\left(E[Y|X=x], \sqrt{Var(Y|X=x)}\right)
f Y ∣ X ( y ∣ x ) = 2 π σ Y 1 − ρ 2 1 exp − 2 1 σ Y 2 ( 1 − ρ 2 ) ( y − μ Y − ρ σ Y ( x − μ X ) / σ X ) 2 = N ( μ Y + ρ σ Y ( σ X x − μ X ) , σ Y 2 ( 1 − ρ 2 ) ) = N ( E [ Y ∣ X = x ] , Va r ( Y ∣ X = x ) )
Or, normalized:
f Y ∣ X ( y ∣ x ) = 1 2 π 1 − ρ 2 e − 1 2 ( y − ρ x ) 2 1 − ρ 2 = N ( ρ x , 1 − ρ 2 ) f_{Y \mid X}(y \mid x)=\frac{1}{\sqrt{2 \pi} \sqrt{1-\rho^2}} e^{-\frac{1}{2} \frac{(y-\rho x)^2}{1-\rho^2}}
\\ = N(\rho x, 1 - \rho^2)
f Y ∣ X ( y ∣ x ) = 2 π 1 − ρ 2 1 e − 2 1 1 − ρ 2 ( y − ρ x ) 2 = N ( ρ x , 1 − ρ 2 )
Unconstrained estimator g g g
g ∗ ( x ) = L ∗ ( x ) = E [ Y ∣ X = x ] = μ Y + ρ σ Y ( x − μ X σ X ) g^*(x) = L^*(x)=E[Y|X=x]=\mu_Y + \rho\sigma_Y\left(\frac{x-\mu_X}{\sigma_X}\right)
g ∗ ( x ) = L ∗ ( x ) = E [ Y ∣ X = x ] = μ Y + ρ σ Y ( σ X x − μ X )