Distributed System (10)
Leader Election
- Any process can call for an election.
- A process can call for at most one election at a time.
- Multiple processes are allowed to call an election simultaneously.
- All of them together must yield only a single leader
- The result of an election should not depend on which process
calls for it.
Election Problem
A run of the election algorithm must always guarantee:
- Safety: For all non-faulty processes p:
- p has elected:
- (q: a particular non-faulty process with the best attribute value)
- or Null
- p has elected:
- Liveness: For all election runs:
- election run terminates
- for all non-faulty processes p: p’s elected is not Null
At the end of the election protocol, the non-faulty process with the
best (highest) election attribute value is elected.
Classical Election Algorithms
Ring election algorithm
- N processes are organized in a logical ring
- All messages are sent clockwise around the ring.

Ring Election Protocol
- When start election
- send election message with ’s to ring successor.
- set state to participating
- When receives message (election, ) from predecessor
- If :
- forward message (election, ) to successor
- set state to participating
- If <
- If (not participating):
- send (election, ) to successor
- set state to participating
- If (not participating):
- If = : is the elected leader (why?)
- send elected message containing ’s id.
- If :
- elected message forwarded along the ring until it reaches the leader.
- Set state to not participating when an elected message is received.
Performance Analysis
- assume no failures occur during the election protocol itself, and there are processes.
- assume that only one process initiates the algorithm
- Bandwidth usage (total number of messages)
- : Worst case ; Best case = .
- turnaround time.
- Bandwidth usage (total number of messages)
- When each process initiates the algorithm:
- messages in best-case.
- messages in worst-case.
- turnaround time.
- assume that only one process initiates the algorithm
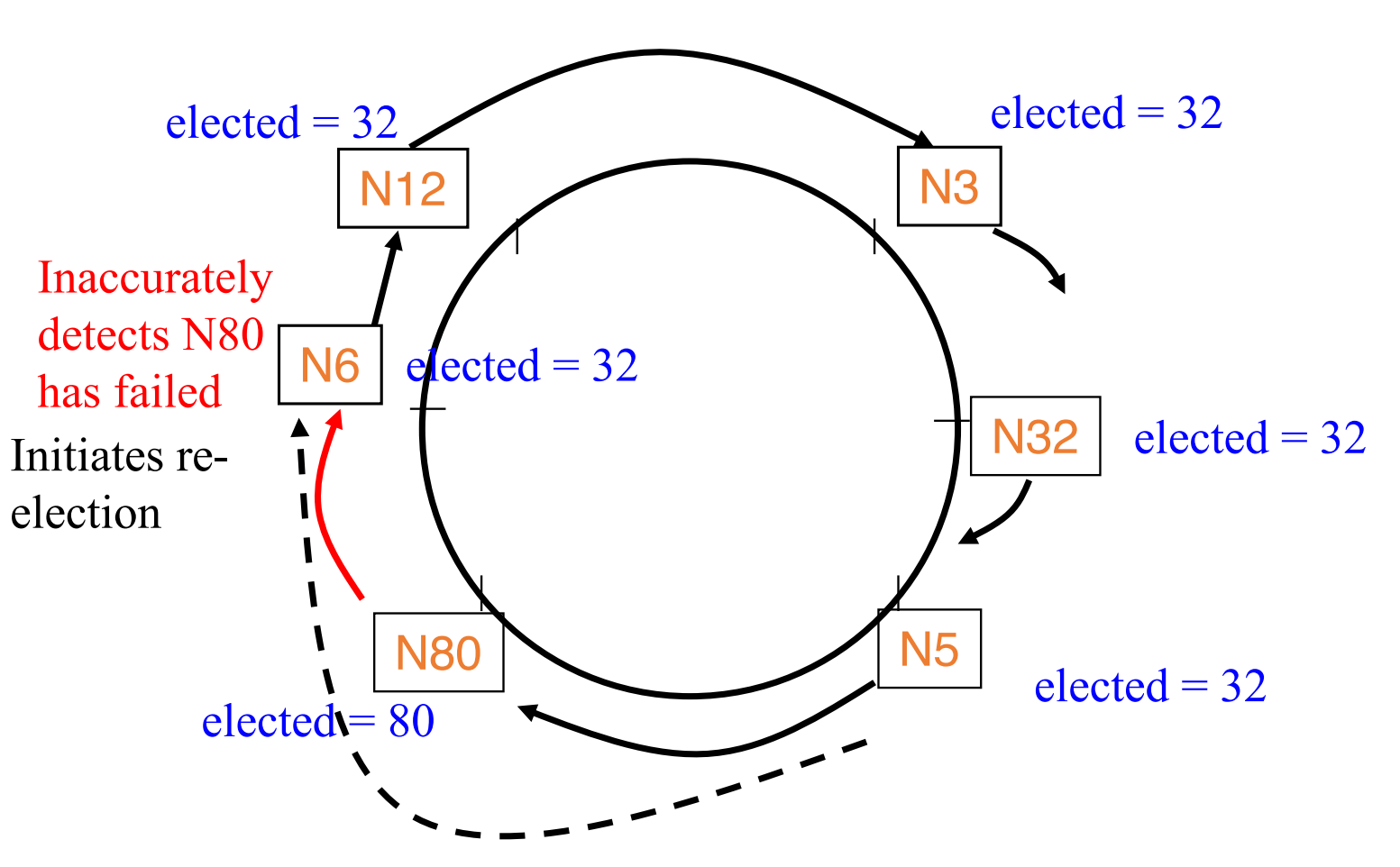
Handling Failures
- A process can detect failure of a process via its own local failure detector:
- Repair the ring.
- Stop forwarding message on failed process
- Start a new run of leader election.
- failure detectors cannot be both complete and accurate.
- Incomplete FD: violation of liveness
- Inaccurate FD: violation of safety.
Bully algorithm
When a process wants to initiate an election:
- if it knows its id is the highest
- it elects itself as coordinator
- sends a Coordinator message to all processes with lower identifiers. Election is completed.
- else it initiates an election by sending an Election message
- Sends it to only processes that have a higher id than itself.
- if receives no answer within timeout
- calls itself leader and sends Coordinator message to all lower id processes. Election completed.
- if an answer received however, then
- there is some non-faulty higher process.
- wait for coordinator message. If none received after another timeout, start a new election run.
A process that receives an Election message replies with disagree message,
and starts its own leader election protocol (unless it has already done so).

Timeout values
Assume the one-way message transmission time (T) is known.
- first timeout: 2T + (processing time) ≈ 2T
Performance Analysis
Best-case
- Turnaround time: 1 message transmission time (T)
- if Highest remaining id initiates election.
Worst-case
- Turnaround time: 4 message transmission times (4T)
- if any lower id process detects failure and starts election.
Distributed System (10)
https://yzzzf.xyz/2024/02/23/distributed-system-10/