Markov Decision Processes
Infinite-horizon discounted MDPs
An MDP M = ( S , A , P , R , γ ) M = (S, A, P, R, \gamma) M = ( S , A , P , R , γ )
State space S S S Action space A A A Transition function P P P S × A → Δ ( S ) S \times A \rightarrow \Delta(S) S × A → Δ ( S ) Δ ( S ) \Delta(S) Δ ( S ) probability simplex over S S S ∣ S ∣ | S| ∣ S ∣ 1 1 1 Reward function R R R S × A → R S \times A \rightarrow \mathbb{R} S × A → R Discount factor γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ ∈ [ 0 , 1 ]
The agent
starts in some state s 1 s_1 s 1
takes action a 1 a_1 a 1
receives reward r 1 = R ( s 1 , a 1 ) r_1 = R(s_1, a_1) r 1 = R ( s 1 , a 1 )
transitions to s 2 ∼ P ( s 1 , a 1 ) s_2 \sim P(s_1, a_1) s 2 ∼ P ( s 1 , a 1 )
takes action a 2 a_2 a 2
… and so on so forth — the process continues forever.
Objective: (discounted) expected total reward
Other terms used: return, value, utility, long-term reward, etc
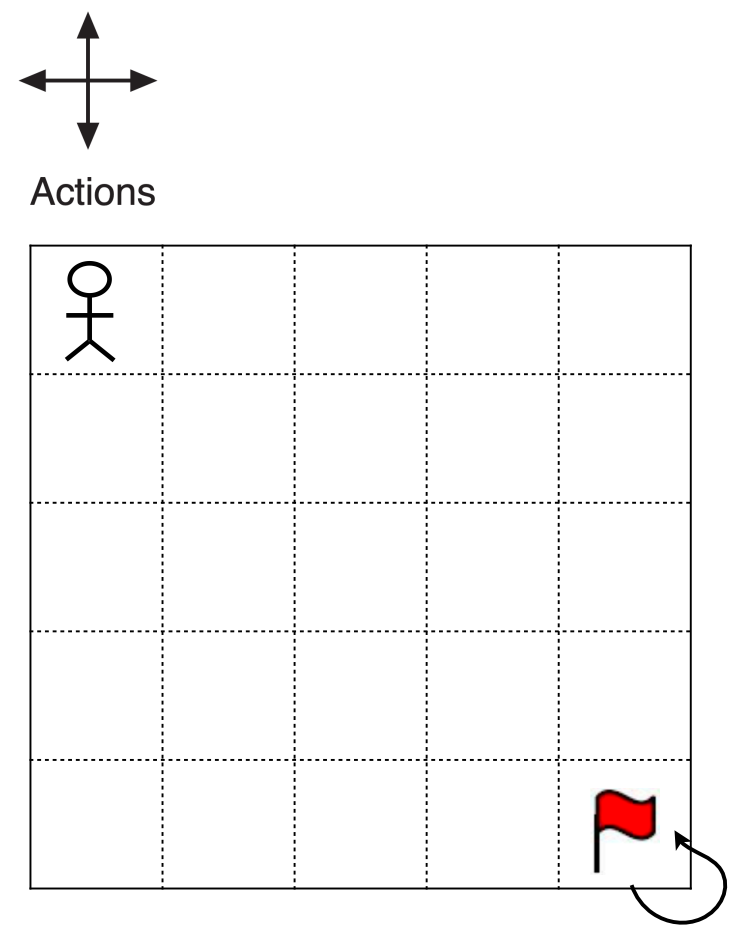
Example: Gridworld
State: grid x, y
Action: N, S, E, W
Dynamics:
most cases: move to adjacent grid
meet wall or reached goal: keep in the current state
Reward:
0 0 0 − 1 -1 − 1
Discount factor γ \gamma γ
discounting
$\gamma = 1 a l l o w s s o m e s t r a t e g i e s t o o b t a i n allows some strategies to obtain a ll o w sso m es t r a t e g i es t oo b t ain
For γ < 1 \gamma < 1 γ < 1
finite horizon vs. infinite-horizon discounted MDP
For finite-horizon (finite acitons), γ \gamma γ 1 1 1
For infinite-horizon (infinite acitons), γ < 1 \gamma < 1 γ < 1
Value and policy
Take action that maximize
E [ ∑ t = 1 ∞ γ t − 1 r t ] \mathbb{E}\left[\sum_{t=1}^{\infty} \gamma^{t-1} r_t\right]
E [ t = 1 ∑ ∞ γ t − 1 r t ]
assume r t ∈ [ 0 , R max ] r_t \in [0, R_{\max}] r t ∈ [ 0 , R m a x ]
E [ ∑ t = 1 ∞ γ t − 1 r t ] ∈ [ 0 , R max 1 − γ ] . \mathbb{E}\left[\sum_{t=1}^{\infty} \gamma^{t-1} r_t\right]
\in \left[0,\frac{R_{\max}}{1-\gamma} \right].
E [ t = 1 ∑ ∞ γ t − 1 r t ] ∈ [ 0 , 1 − γ R m a x ] .
A policy describes how the agent acts at a state:
a t = π ( s t ) a_t = \pi(s_t)
a t = π ( s t )
define value funtion
V π ( s ) = E [ ∑ t = 1 ∞ γ t − 1 r t | s 1 = s , π ] V^\pi (s) = \mathbb{E}\left[\sum_{t=1}^{\infty} \gamma^{t-1} r_t \middle| s_1 = s, \pi \right]
V π ( s ) = E [ t = 1 ∑ ∞ γ t − 1 r t s 1 = s , π ]
Bellman Equation
V π ( s ) = E [ ∑ t = 1 ∞ γ t − 1 r t | s 1 = s , π ] = R ( s , π ( s ) ) + γ ⟨ P ( ⋅ | s , π ( s ) ) , V π ( ⋅ ) ⟩ \begin{aligned}
V^\pi(s) & =\mathbb{E}\left[\sum_{t=1}^{\infty} \gamma^{t-1} r_t \middle| s_1=s, \pi\right] \\
& =R(s, \pi(s))+\gamma\left\langle P(\cdot \middle| s, \pi(s)), V^\pi(\cdot)\right\rangle
\end{aligned}
V π ( s ) = E [ t = 1 ∑ ∞ γ t − 1 r t s 1 = s , π ] = R ( s , π ( s )) + γ ⟨ P ( ⋅ ∣ s , π ( s )) , V π ( ⋅ ) ⟩
Detailed steps
V π ( s ) = E [ ∑ t = 1 ∞ γ t − 1 r t | s 1 = s , π ] = E [ r 1 + ∑ t = 2 ∞ γ t − 1 r t | s 1 = s , π ] = R ( s , π ( s ) ) + ∑ s ′ ∈ S P ( s ′ | s , π ( s ) ) E [ γ ∑ t = 2 ∞ γ t − 2 r t | s 1 = s , s 2 = s ′ , π ] = R ( s , π ( s ) ) + ∑ s ′ ∈ S P ( s ′ | s , π ( s ) ) E [ γ ∑ t = 2 ∞ γ t − 2 r t | s 2 = s ′ , π ] = R ( s , π ( s ) ) + γ ∑ s ′ ∈ S P ( s ′ | s , π ( s ) ) E [ ∑ t = 1 ∞ γ t − 1 r t | s 1 = s ′ , π ] = R ( s , π ( s ) ) + γ ∑ s ′ ∈ S P ( s ′ | s , π ( s ) ) V π ( s ′ ) = R ( s , π ( s ) ) + γ ⟨ P ( ⋅ | s , π ( s ) ) , V π ( ⋅ ) ⟩ \begin{aligned}
V^\pi(s) & =\mathbb{E}\left[\sum_{t=1}^{\infty} \gamma^{t-1} r_t \middle| s_1=s, \pi\right] \\
& =\mathbb{E}\left[r_1+\sum_{t=2}^{\infty} \gamma^{t-1} r_t \middle| s_1=s, \pi\right] \\
& =R(s, \pi(s))+\sum_{s^{\prime} \in \mathcal{S}} P\left(s^{\prime} \middle| s, \pi(s)\right) \mathbb{E}\left[\gamma \sum_{t=2}^{\infty} \gamma^{t-2} r_t \middle| s_1=s, s_2=s^{\prime}, \pi\right] \\
& =R(s, \pi(s))+\sum_{s^{\prime} \in \mathcal{S}} P\left(s^{\prime} \middle| s, \pi(s)\right) \mathbb{E}\left[\gamma \sum_{t=2}^{\infty} \gamma^{t-2} r_t \middle| s_2=s^{\prime}, \pi\right] \\
& =R(s, \pi(s))+\gamma \sum_{s^{\prime} \in \mathcal{S}} P\left(s^{\prime} \middle| s, \pi(s)\right) \mathbb{E}\left[\sum_{t=1}^{\infty} \gamma^{t-1} r_t \middle| s_1=s^{\prime}, \pi\right] \\
& =R(s, \pi(s))+\gamma \sum_{s^{\prime} \in \mathcal{S}} P\left(s^{\prime} \middle| s, \pi(s)\right) V^\pi\left(s^{\prime}\right) \\
& =R(s, \pi(s))+\gamma\left\langle P(\cdot \middle| s, \pi(s)), V^\pi(\cdot)\right\rangle
\end{aligned}
V π ( s ) = E [ t = 1 ∑ ∞ γ t − 1 r t s 1 = s , π ] = E [ r 1 + t = 2 ∑ ∞ γ t − 1 r t s 1 = s , π ] = R ( s , π ( s )) + s ′ ∈ S ∑ P ( s ′ ∣ s , π ( s ) ) E [ γ t = 2 ∑ ∞ γ t − 2 r t s 1 = s , s 2 = s ′ , π ] = R ( s , π ( s )) + s ′ ∈ S ∑ P ( s ′ ∣ s , π ( s ) ) E [ γ t = 2 ∑ ∞ γ t − 2 r t s 2 = s ′ , π ] = R ( s , π ( s )) + γ s ′ ∈ S ∑ P ( s ′ ∣ s , π ( s ) ) E [ t = 1 ∑ ∞ γ t − 1 r t s 1 = s ′ , π ] = R ( s , π ( s )) + γ s ′ ∈ S ∑ P ( s ′ ∣ s , π ( s ) ) V π ( s ′ ) = R ( s , π ( s )) + γ ⟨ P ( ⋅ ∣ s , π ( s )) , V π ( ⋅ ) ⟩
where ⟨ ⋅ , ⋅ ⟩ \langle\cdot, \cdot\rangle ⟨ ⋅ , ⋅ ⟩
V π V^\pi V π ∣ S ∣ × 1 | S| \times 1 ∣ S ∣ × 1 [ V π ( s ) ] s ∈ S [V^\pi(s)]_{s \in S} [ V π ( s ) ] s ∈ S R π R^\pi R π [ R ( s , π ( s ) ) ] s ∈ S [R(s, \pi(s))]_{s \in S} [ R ( s , π ( s )) ] s ∈ S P π P^\pi P π [ P ( s ′ ∣ s , π ( s ) ) ] s ∈ S , s ′ ∈ S [P(s' | s, \pi(s))]_{s \in S, s' \in S} [ P ( s ′ ∣ s , π ( s )) ] s ∈ S , s ′ ∈ S
V π = R π + γ P π V π ( I − γ P π ) V π = R π V π = ( I − γ P π ) − 1 R π \begin{gathered}
V^\pi = R^\pi + \gamma P^\pi V^\pi \\
(I - \gamma P^\pi)V^\pi = R^\pi \\
V^\pi = (I - \gamma P^\pi)^{-1}R^\pi \\
\end{gathered}
V π = R π + γ P π V π ( I − γ P π ) V π = R π V π = ( I − γ P π ) − 1 R π
Claim: ( I − γ P ) (I - \gamma P) ( I − γ P )
Proof. It suffies to prove
∀ x ≠ 0 ⃗ ∈ R S , ( I − γ P π ) x ≠ 0 ⃗ \forall x \ne \vec{0} \in \mathbb{R}^S, \; (I - \gamma P^\pi)x \ne \vec{0}
∀ x = 0 ∈ R S , ( I − γ P π ) x = 0
then
∥ ( I − γ P π ) x ∥ ∞ = ∥ x − γ P π x ∥ ∞ ≥ ∥ x ∥ ∞ − γ ∥ P π x ∥ ∞ ≥ ∥ x ∥ ∞ − γ ∥ x ∥ ∞ = ( 1 − γ ) ∥ x ∥ ∞ ≥ ∥ x ∥ ∞ > 0 ■ \begin{aligned}
&\| (I - \gamma P^\pi) x \| _{\infty} \\
=&\| x - \gamma P^\pi x \| _{\infty} \\
\ge&\| x\| _{\infty} - \gamma\| P^\pi x \| _{\infty} \\
\ge&\| x\| _{\infty} - \gamma\| x\| _{\infty} \\
=&(1 - \gamma)\| x\| _{\infty} \\
\ge&\| x\| _{\infty} \\
>& 0 \blacksquare
\end{aligned}
= ≥ ≥ = ≥ > ∥ ( I − γ P π ) x ∥ ∞ ∥ x − γ P π x ∥ ∞ ∥ x ∥ ∞ − γ ∥ P π x ∥ ∞ ∥ x ∥ ∞ − γ ∥ x ∥ ∞ ( 1 − γ ) ∥ x ∥ ∞ ∥ x ∥ ∞ 0 ■
Generalize to stochastic policies
V π ( s ) = E a ∼ π ( ⋅ ∣ s ) , s ′ ∼ P ( ⋅ ∣ s , a ) [ R ( s , a ) + γ V π ( s ′ ) ] V^\pi(s) =
\mathbb{E}_{a \sim \pi(\cdot \mid s), s^{\prime} \sim P(\cdot \mid s, a)}\left[R(s, a)+\gamma V^\pi\left(s^{\prime}\right)\right]
V π ( s ) = E a ∼ π ( ⋅ ∣ s ) , s ′ ∼ P ( ⋅ ∣ s , a ) [ R ( s , a ) + γ V π ( s ′ ) ]
V π = R π + γ P π V π V^\pi = R^\pi + \gamma P^\pi V^\pi
V π = R π + γ P π V π
still holds for
R π ( s ) = E a ∼ π ( ⋅ ∣ s ) [ R ( s , a ) ] P π ( s ′ ∣ s ) = ∑ a ∈ A π ( a ∣ s ) P ( s ′ ∣ s , a ) \begin{aligned}
& R^\pi(s)=\mathbb{E}_{a \sim \pi(\cdot \mid s)}[R(s, a)] \\
& P^\pi\left(s^{\prime} \mid s\right)=\sum_{a \in \mathcal{A}} \pi(a \mid s) P\left(s^{\prime} \mid s, a\right)
\end{aligned}
R π ( s ) = E a ∼ π ( ⋅ ∣ s ) [ R ( s , a )] P π ( s ′ ∣ s ) = a ∈ A ∑ π ( a ∣ s ) P ( s ′ ∣ s , a )
Optimality
For infinite-horizon discounted MDPs, there always exists a stationary and deterministic policy that is optimal for all starting states simultaneously.
Optimal policy π ⋆ \pi^\star π ⋆
V ⋆ : = V π ⋆ V^\star := V^{\pi^\star }
V ⋆ := V π ⋆
Bellman Optimality Equation
V ∗ ( s ) = max a ∈ A ( R ( s , a ) + γ E s ′ ∼ P ( s , a ) [ V ∗ ( s ′ ) ] ) V^{*}(s)=\max_{a\in A}\left(R(s,a)+\gamma\mathbb{E}_{s^{\prime}\thicksim P(s,a)}\left[V^{*}(s^{\prime})\right]\right)
V ∗ ( s ) = a ∈ A max ( R ( s , a ) + γ E s ′ ∼ P ( s , a ) [ V ∗ ( s ′ ) ] )
Q-functions
Q π ( s , a ) : = E [ ∑ t = 1 ∞ γ t − 1 r t | s 1 = s , a 1 = a ; π ] Q ⋆ : = Q π ⋆ or V π ( s ) = Q π ( s , π ( s ) ) or Q π ( s , π ) \begin{gathered}
Q^{\pi}(s,a):=\mathbb{E}\left[\sum_{t=1}^{\infty}\gamma^{t-1}r_{t} \middle| s_1=s, a_1=a; \pi \right] \\
Q^\star := Q^{\pi^\star } \; \text{or} \\
V^{\pi}(s)=Q^{\pi}(s,\pi(s)) \;\; \text{or} \;\; Q^{\pi}(s,\pi)\\
\end{gathered}
Q π ( s , a ) := E [ t = 1 ∑ ∞ γ t − 1 r t s 1 = s , a 1 = a ; π ] Q ⋆ := Q π ⋆ or V π ( s ) = Q π ( s , π ( s )) or Q π ( s , π )
Bellman equation for Q Q Q
Q π ( s , a ) = R ( s , a ) + γ E s ′ ∼ P ( ⋅ ∣ s , a ) [ Q π ( s ′ , π ) ] Q ⋆ ( s , a ) = R ( s , a ) + γ E s ′ ∼ P ( ⋅ ∣ s , a ) [ max a ′ ∈ A Q ⋆ ( s ′ , a ′ ) ] \begin{gathered}
Q^{\pi}(s,a)=R(s,a)+\gamma\mathbb{E}_{s^{\prime}\sim P(\cdot|s,a)}\left[Q^{\pi}(s^{\prime},\pi)\right] \\
Q^\star (s,a)=R(s,a)+\gamma\mathbb{E}_{s^{\prime}\sim P(\cdot|s,a)}\left[\max_{a^{\prime}\in A}Q^\star (s^{\prime},a^{\prime})\right]
\end{gathered}
Q π ( s , a ) = R ( s , a ) + γ E s ′ ∼ P ( ⋅ ∣ s , a ) [ Q π ( s ′ , π ) ] Q ⋆ ( s , a ) = R ( s , a ) + γ E s ′ ∼ P ( ⋅ ∣ s , a ) [ a ′ ∈ A max Q ⋆ ( s ′ , a ′ ) ]
Define optimal V V V π \pi π Q Q Q
V ∗ ( s ) = max a ∈ A Q ∗ ( s , a ) = Q ∗ ( s , π ∗ ( s ) ) V^{*}(s)=\max_{a\in A}Q^{*}(s,a)=Q^{*}(s,\pi^{*}(s))
V ∗ ( s ) = a ∈ A max Q ∗ ( s , a ) = Q ∗ ( s , π ∗ ( s ))
π ⋆ ( s ) = arg max a ∈ A Q ⋆ ( s , a ) \pi^\star (s) = \argmax_{a \in A} Q^\star (s, a)
π ⋆ ( s ) = a ∈ A arg max Q ⋆ ( s , a )
Fixed-horizon MDPs
Specified by ( S , A , R , P , H ) (S, A, R, P, H) ( S , A , R , P , H ) H H H
V H + 1 π ≡ 0 V h π ( s ) = R ( s , π ( s ) ) + E s ′ ∼ P ( s , a ) [ V h + 1 π ( s ′ ) ] \begin{gathered}
V_{H+1}^\pi \equiv 0 \\
V_{h}^{\pi}(s)=R(s,\pi(s))+\mathbb{E}_{s'\sim P(s,a)}[V_{h+1}^{\pi}(s')]
\end{gathered}
V H + 1 π ≡ 0 V h π ( s ) = R ( s , π ( s )) + E s ′ ∼ P ( s , a ) [ V h + 1 π ( s ′ )]