Reinforcement Learning (1)
example: Shortest Path
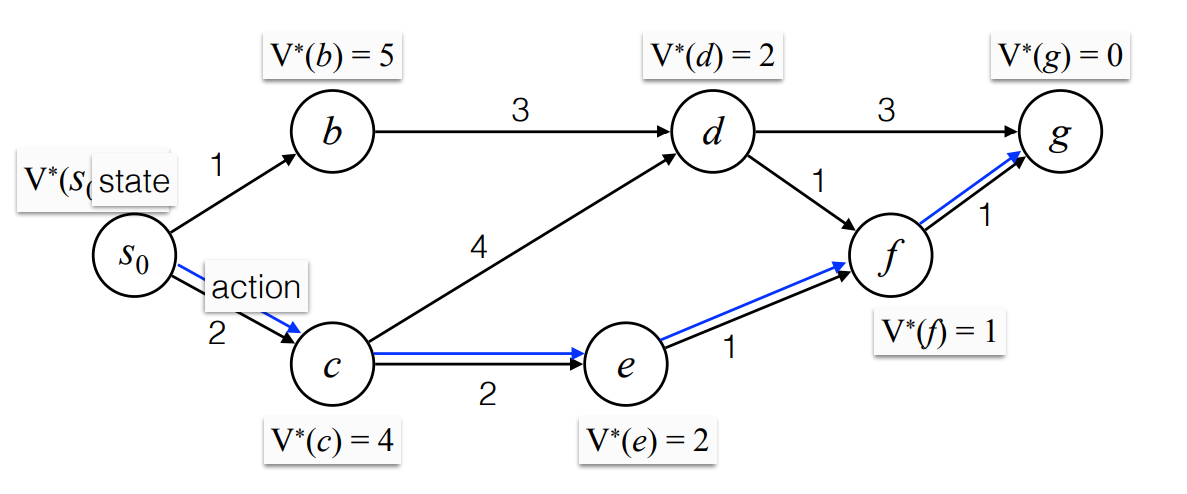
Shortest Path
- nodes: stats
- edges: actions
Greedy is not optimal.
Bellman Equation (Dynamic Programing):
Stochastic Shortest Path
Markov Decision Process (MDP)
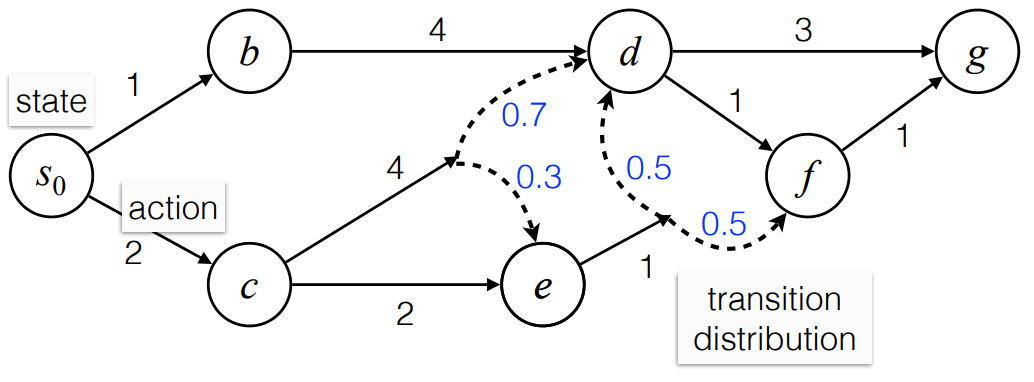
Stochastic Shortest Path
Bellman Equation
optimal policy :
Model-based RL
The states are unknown.
Learn by trial-and-error
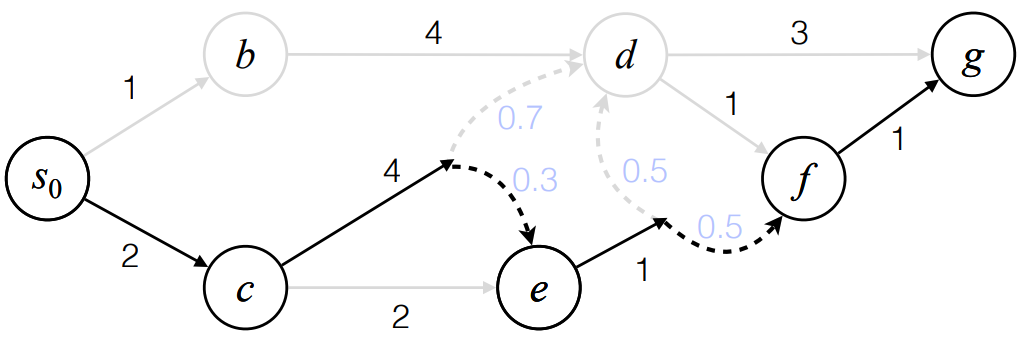
a trajectory: s0>c>e>F>G
Need to recover the graph by collecting multiple trajectories.
Use imperial frequency to find probabilities.
Assume states & actions are visited uniformly.
exploration problem
Random exploration can be inefficient:
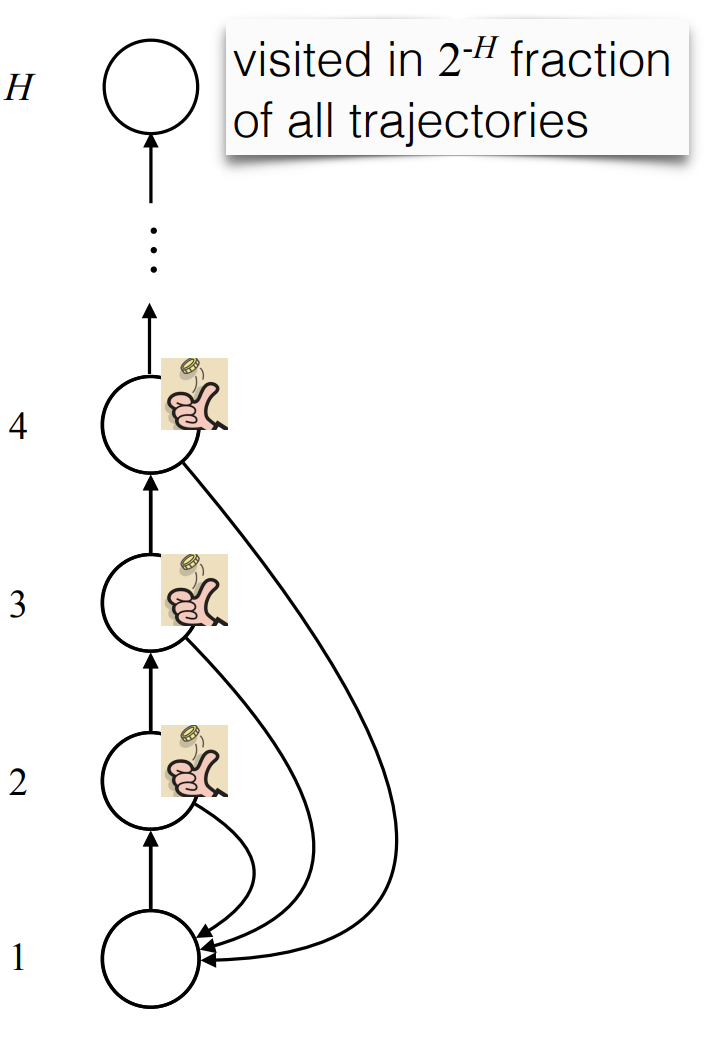
example: video game
example: video game
Objective: maximize the reward
Problem: the graph is too large
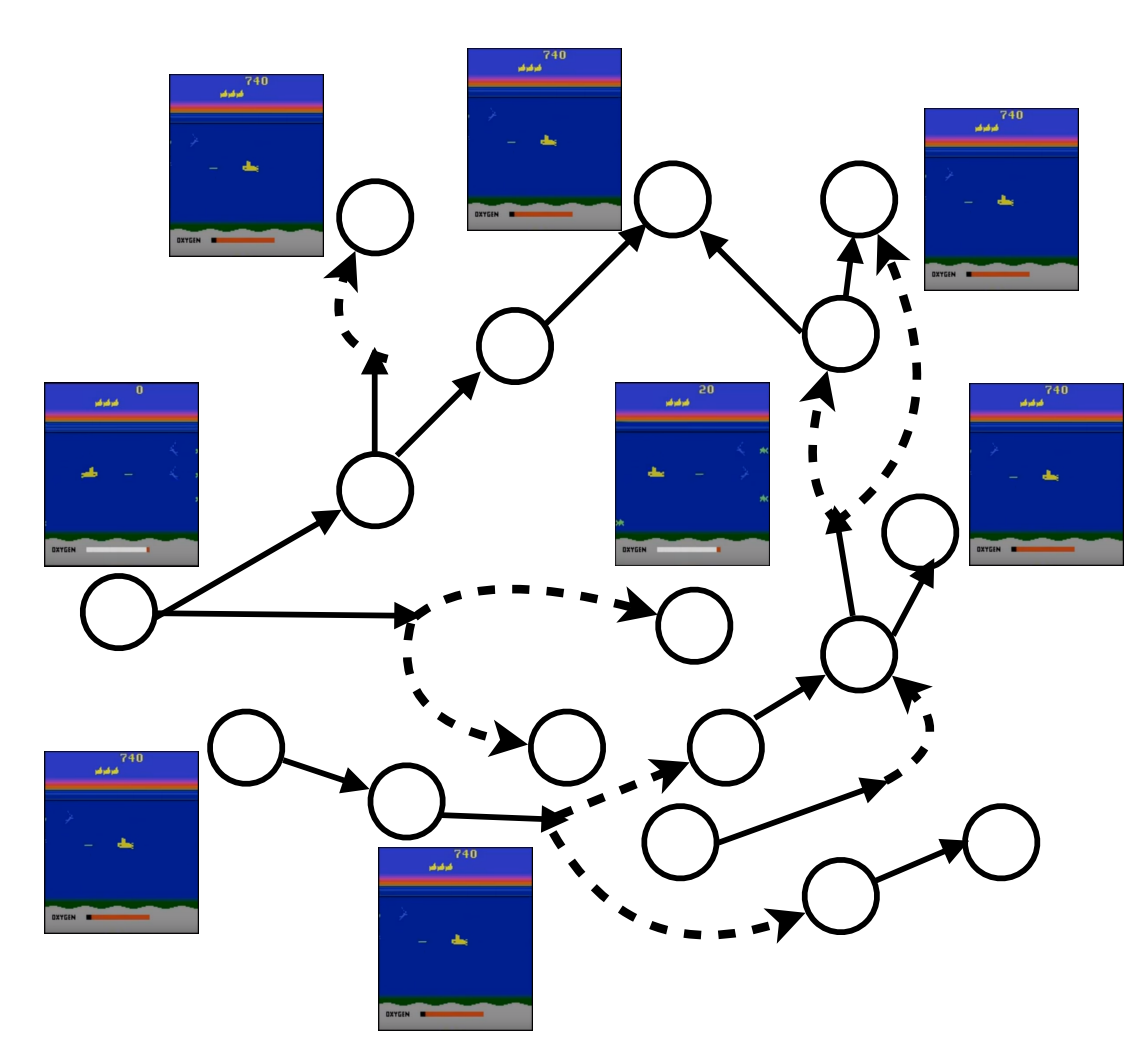
There are states that the RL model have never seen, therefore need generalization
Contextual bandits
- Even if the algorithm is good, if mamke bad actions at beginning, will not get good data.
- Keep taking bad actions (e.g. guessing wrong label on image classification), don’t know right action.
- Compared with superivsed learning
- Multi-armed bandit
RL steps
For round t = 1, 2, …,
- For time step h=1, 2, …, H, the learner
- Observes
- Chooses
- Receives
- Next is generated as a function of and
(or sometimes, all previous x’s and a’s within round t)
Reinforcement Learning (1)
https://yzzzf.xyz/2024/02/04/reinforcement-learning-lecture-1/